
It’s tempting to think that table partitioning will improve query performance. After all, it’s an Enterprise Edition feature– it must have a lot of magic, right?
Table partitioning does have magic for the right situations. It shines when you want to add a large amount of data to a table or remove a large amount of data in chunks! The “partition switching” feature can essentially help you avoid doing inserts and deletes against a live production table, and it pairs beautifully with cool new features like ColumnStore indexes. For things like fact tables in a data warehouse, it’s drool-worthy.
But for other uses, table partitioning can be a lot of work to implement and it can slow your queries down. And it may not always be obvious to you why your queries are slower. Let’s take a look at a simple example.
Let’s partition the Posts table
We’re using the StackOverflow sample sample database. The Posts table contains questions, answers, and other types of posts, each of which has a different PostTypeId.
Let’s say that our workload does many point lookups on a post based on an integer Id column in the table. We have some aggregate queries that run looking for top scoring questions, recent answers, and things like that, and most of those queries specify PostTypeId. We might be tempted to partition the table on PostTypeId.
For comparison purposes, we create two tables with the exact same columns, data types, and rowcounts:
- dbo.PostsNarrow has a unique clustered index on the Id column
- dbo.PostsPartitioned is partitioned on PostTypeId and has a unique clustered index on Id, PostTypeId
For queries that do specify PostTypeId, we’re hoping that we can get partition elimination. (This can be tricky sometimes due to bugs with min/max syntax, or weird implicit conversion issues, or even optimizer issues with joins). But performance can also be tricky for simple queries which don’t specify PostTypeId, even when partition elimination isn’t an issue.
Our example query
Our example query pulls the people who are most active– they write the most questions and answers. Here’s the version of the query that runs against PostsNarrow:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
WITH freq AS ( SELECT TOP 100 OwnerUserId, COUNT(*) as PostCount FROM dbo.PostsNarrow GROUP BY OwnerUserId ORDER BY COUNT(*) DESC ) SELECT u.DisplayName, freq.PostCount FROM freq JOIN dbo.Users u on u.Id=freq.OwnerUserId; GO |
We have the following index on both PostsNarrow and PostsPartitioned. (The included columns are to support other queries.)
|
1 2 3 |
CREATE INDEX ix_Posts_OwnerUserId_INCLUDES on dbo.PostsPartitioned (OwnerUserId) INCLUDE (PostTypeId, AcceptedAnswerId, CreationDate, LastEditorUserId) GO |
Run against the non-partitioned table, this query uses 3344 ms of CPU time and has an elapsed time of 1039 ms.
Just changing the query to run against dbo.PostsPartitioned, the query goes to 5672 ms of CPU time and the elapsed time is 2437 ms– it’s twice as slow!
The secret is in the execution plans
Comparing the plans for the two queries, we can see that SQL Server is doing something different inside the CTE where it groups by OwnerUserId.
Non-Partitioned Plan Excerpt (showing actual row counts):

Partitioned Plan Excerpt (showing actual row counts):
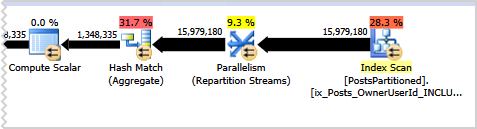
The Non-Partitioned plan is able to stream the data from the index scan directly into a stream aggregate operator to do the group by OwnerUserId. The partitioned plan has to repartition the streams, then it has to put all the data in a Hash Match aggregate and compare all the buckets.
The hash match aggregate is more work
The hash match operator is what’s slowing this query down– it requires a larger memory grant and it has to do more work. But SQL Server has to use it for our query because our non-clustered index on OwnerUserId is partitioned.
In other words, the data in PostsPartitioned’s OwnerUserId index is like this:
- PostTypeId=1
- All rows ordered by OwnerUserId for this PostTypeId with included columns
- PostTypeId=2
- All rows ordered by OwnerUserId for this PostTypeId with included columns
- PostTypeId=3
- All rows ordered by OwnerUserId for this PostTypeId with included columns
Any given OwnerUserId can be in multiple partitions, and we have to find them all. That’s why we can’t use the stream aggregate operator.
Can’t we create a non-aligned index?
We can! We have the option to create a non-aligned (non-partitioned) index on dbo.PostsPartitioned’s OwnerUserId column. Since it’s not partitioned, everything is purely sorted by OwnerUserId and we can get the stream aggregate back.
But, wait a second. Let’s pause and think about this.
The whole point of using table partitioning was to partition things. Creating a bunch of non-aligned indexes is tantamount to admitting defeat: we can’t get partition elimination against those indexes for queries that DO use the partitioning key. (There are other downsides, too, like preventing partition switching.) And we will get into a whole different set of problems if we have to keep partitioned and non-partitioned copies of the same index.
This is just a simple example. What if it were more complex?
I’m going to let you in on a little secret: it took me a bit of time looking at this example to figure out why query 2 was slower. There were several red herrings that I fixed before writing this post regarding statistics differences between the tables that distracted me for a few minutes more time than I’m willing to admit.
And I had to think back to some of Jeremiah’s modules in our Advanced Querying and Indexing course to remember the difference between those two operators.
And the first time I created a non-aligned index on the partitioned table to verify I could get the stream aggregate operator back, I accidentally created it as aligned at first and got more confused.
Admittedly, I enjoy this kind of thing and am saving another example of a query that goes from 1 ms to 11 seconds for a treat to dig into and write a fun demo with, but most people would rather just keep the 1ms query and not worry about it!
Let’s sum it up
Here’s what to take away from all of this:
- Table partitioning can make some queries slower
- Partitioning adds complexity to troubleshooting and tuning queries– it’s time consuming and takes longer
- Non-aligned indexes aren’t an easy answer: if we need to resort to a lot of them, how much are we actually benefitting from table partitioning?
For these reasons, table partitioning is typically not a great fit for SQL Servers with an OLTP pattern where slow queries are the biggest pain point. Traditional index tuning and query rewrites will usually get you better performance with less hassle.
Wanna learn more about indexing? Check out our online course on tuning indexes in SQL Server.

9 Comments. Leave new
Thank you! I’ve heard many people say there was magic to be found in partitioning quoting the advertised benefits, but never seeing the unadvertised costs and risks. I knew through testing that things went both ways, but never got to the point where I could reproduce it generically, put it in simple words, and be able to share it with everyone. Now I have somewhere to point people, and that makes a big difference when you’re just asking people to trust you that it’s not a magical all-purpose unicorn.
Oh, thanks for writing this! That’s a huge compliment about the post. Means a lot.
“It pairs beautifully with cool new features like ColumnStore indexes. For things like fact tables in a data warehouse, it’s drool-worthy.”
I just implemented date-based partitioning on a few columnstore-based fact tables, as it happens! Our primary goal was to get some performance benefits from partition elimination, but the queries have to be just right for that…now we have a side benefit where we only have to do occasional rebuilds of the last partition (ie., current year) to clean up columnstore “fragmentation” (if that’s what you call it…). Better than a full table rebuild, anyway, if there isn’t a lot of delta/deleted records in the older partitions.
I will say, adding partitioning to a clustered columnstore index is not without some weirdness…make sure you have plenty of disk space, as it will want you to convert it to a heap, then a B-tree (based on partitioning), then a heap again, then back into the highly compressed columnstore index, so if you’ve become acclimated to the excellent compression of the columnstore, it can be a bit of a shock to decompress it to full size again!
Sorry, old thread. We have a large table where it’s properties in management studio shows “not partitioned.” There is a clustered primary key. There is also a unique non-clustered index that is partitioned. This is actually what I think of when I hear “non-aligned” index. Since the few partitions leave out most of our customers added since this was put in place by development, I’ve been investigating performance issues and whether to just “get rid of it.” I have found some queries that wind up using that index and have very large estimated/actual row variances in the plans. A query hint specifying a more appropriate index reduces runtime from ten minutes plus to a few seconds. Oddly, just getting rid of the order by clause does the same thing.
Randy – I’m not sure if you’re asking a question or just posting a comment, but if it’s a question, try narrowing it down to what you’re asking, and then put it up on http://dba.stackexchange.com.
##we can’t get partition elimination against those indexes for queries that DO use the partitioning key##
Could you please more elaborate. You meant to say partition elimination for any query will not work?
Thank you for great post
Manish – that section talks about non-aligned indexes – indexes that don’t align to the partitioning key.
Hello All
I have created Physical partition in CompanyID in my table having millions of records for each company.
Also, I have used CompanyId In all my queries to get partition elimination benefit, but I found one problem when i have used the Company id column in where part with in clause and id stored in Temporary table and cheked the execution plan and, it accessed all the paritions. Can you tell me why this thing happen?
Jitesh – for help interpreting a query plan, start here: https://www.brentozar.com/archive/2009/03/getting-help-with-a-slow-query/