
SQL server loves unique indexes
Why? Because it’s lazy. Just like you. If you had to spend all day flipping pages around, you’d probably be even lazier. Thank Codd someone figured out how to make a computer do it. There’s some code below, along with some screen shots, but…
TL;DR
SQL is generally pretty happy to get good information about the data it’s holding onto for you. If you know something will be unique, let it know. It will make better plan choices, and certain operations will be supported more efficiently than if you make it futz around looking for repeats in unique data.
There is some impact on inserts and updates as the constraint is checked, but generally it’s negligible, especially when compared to the performance gains you can get from select queries.
So, without further ado!
Q: What was the last thing the Medic said to the Heavy?
A: Demoooooooooo!
We’ll start off by creating four tables. Two with unique clustered indexes, and two with non-unique clustered indexes, that are half the size. I’m just going with simple joins here, since they seem like a pretty approachable subject to most people who are writing queries and creating indexes. I hope.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 |
USE tempdb /* The drivers */ ;WITH E1(N) AS ( SELECT NULL UNION ALL SELECT NULL UNION ALL SELECT NULL UNION ALL SELECT NULL UNION ALL SELECT NULL UNION ALL SELECT NULL UNION ALL SELECT NULL UNION ALL SELECT NULL UNION ALL SELECT NULL UNION ALL SELECT NULL ), E2(N) AS (SELECT NULL FROM E1 a, E1 b, E1 c, E1 d, E1 e, E1 f, E1 g, E1 h, E1 i, E1 j), Numbers AS (SELECT TOP (1000000) ROW_NUMBER() OVER (ORDER BY (SELECT NULL)) AS N FROM E2) SELECT ISNULL(N.N, 0) AS ID, ISNULL(CONVERT(DATE, DATEADD(SECOND, N.N, GETDATE())), '1900-01-01') AS OrderDate, ISNULL(SUBSTRING(CONVERT(VARCHAR(255), NEWID()), 0, 9) , 'AAAAAAAA') AS PO INTO UniqueCL FROM Numbers N; ALTER TABLE UniqueCL ADD CONSTRAINT PK_UniqueCL PRIMARY KEY CLUSTERED (ID) WITH (FILLFACTOR = 100) ;WITH E1(N) AS ( SELECT NULL UNION ALL SELECT NULL UNION ALL SELECT NULL UNION ALL SELECT NULL UNION ALL SELECT NULL UNION ALL SELECT NULL UNION ALL SELECT NULL UNION ALL SELECT NULL UNION ALL SELECT NULL UNION ALL SELECT NULL ), E2(N) AS (SELECT NULL FROM E1 a, E1 b, E1 c, E1 d, E1 e, E1 f, E1 g, E1 h, E1 i, E1 j), Numbers AS (SELECT TOP (1000000) ROW_NUMBER() OVER (ORDER BY (SELECT NULL)) AS N FROM E2) SELECT ISNULL(N.N, 0) AS ID, ISNULL(CONVERT(DATE, DATEADD(SECOND, N.N, GETDATE())), '1900-01-01') AS OrderDate, ISNULL(SUBSTRING(CONVERT(VARCHAR(255), NEWID()), 0, 9) , 'AAAAAAAA') AS PO INTO NonUniqueCL FROM Numbers N; CREATE CLUSTERED INDEX CLIX_NonUnique ON dbo.NonUniqueCL (ID) WITH (FILLFACTOR = 100) /* The joiners */ ;WITH E1(N) AS ( SELECT NULL UNION ALL SELECT NULL UNION ALL SELECT NULL UNION ALL SELECT NULL UNION ALL SELECT NULL UNION ALL SELECT NULL UNION ALL SELECT NULL UNION ALL SELECT NULL UNION ALL SELECT NULL UNION ALL SELECT NULL ), E2(N) AS (SELECT NULL FROM E1 a, E1 b, E1 c, E1 d, E1 e, E1 f, E1 g, E1 h, E1 i, E1 j), Numbers AS (SELECT TOP (1000000) ROW_NUMBER() OVER (ORDER BY (SELECT NULL)) AS N FROM E2) SELECT ISNULL(N.N, 0) AS ID, ISNULL(CONVERT(DATE, DATEADD(SECOND, N.N, GETDATE())), '1900-01-01') AS OrderDate, ISNULL(SUBSTRING(CONVERT(VARCHAR(255), NEWID()), 0, 9) , 'AAAAAAAA') AS PO INTO UniqueJoin FROM Numbers N WHERE N.N < 5000001; ALTER TABLE UniqueJoin ADD CONSTRAINT PK_UniqueJoin PRIMARY KEY CLUSTERED (ID, OrderDate) WITH (FILLFACTOR = 100) ;WITH E1(N) AS ( SELECT NULL UNION ALL SELECT NULL UNION ALL SELECT NULL UNION ALL SELECT NULL UNION ALL SELECT NULL UNION ALL SELECT NULL UNION ALL SELECT NULL UNION ALL SELECT NULL UNION ALL SELECT NULL UNION ALL SELECT NULL ), E2(N) AS (SELECT NULL FROM E1 a, E1 b, E1 c, E1 d, E1 e, E1 f, E1 g, E1 h, E1 i, E1 j), Numbers AS (SELECT TOP (1000000) ROW_NUMBER() OVER (ORDER BY (SELECT NULL)) AS N FROM E2) SELECT ISNULL(N.N, 0) AS ID, ISNULL(CONVERT(DATE, DATEADD(SECOND, N.N, GETDATE())), '1900-01-01') AS OrderDate, ISNULL(SUBSTRING(CONVERT(VARCHAR(255), NEWID()), 0, 9) , 'AAAAAAAA') AS PO INTO NonUniqueJoin FROM Numbers N WHERE N.N < 5000001; CREATE CLUSTERED INDEX CLIX_NonUnique ON dbo.NonUniqueJoin (ID, OrderDate) WITH (FILLFACTOR = 100); |
Now that we have our setup, let’s look at a couple queries. I’ll be returning the results to a variable so we don’t sit around waiting for SSMS to display a bunch of uselessness.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
DECLARE @ID BIGINT; SELECT @ID = uc.ID FROM dbo.UniqueCL AS uc JOIN dbo.UniqueJoin AS uj ON uj.ID = uc.ID WHERE uc.ID % 2 = 0 ORDER BY uc.ID; GO DECLARE @ID BIGINT; SELECT @ID = nuc.ID FROM dbo.NonUniqueCL AS nuc JOIN dbo.NonUniqueJoin AS nuj ON nuj.ID = nuc.ID WHERE nuc.ID % 2 = 0 ORDER BY nuc.ID; GO |
What does SQL do with these?
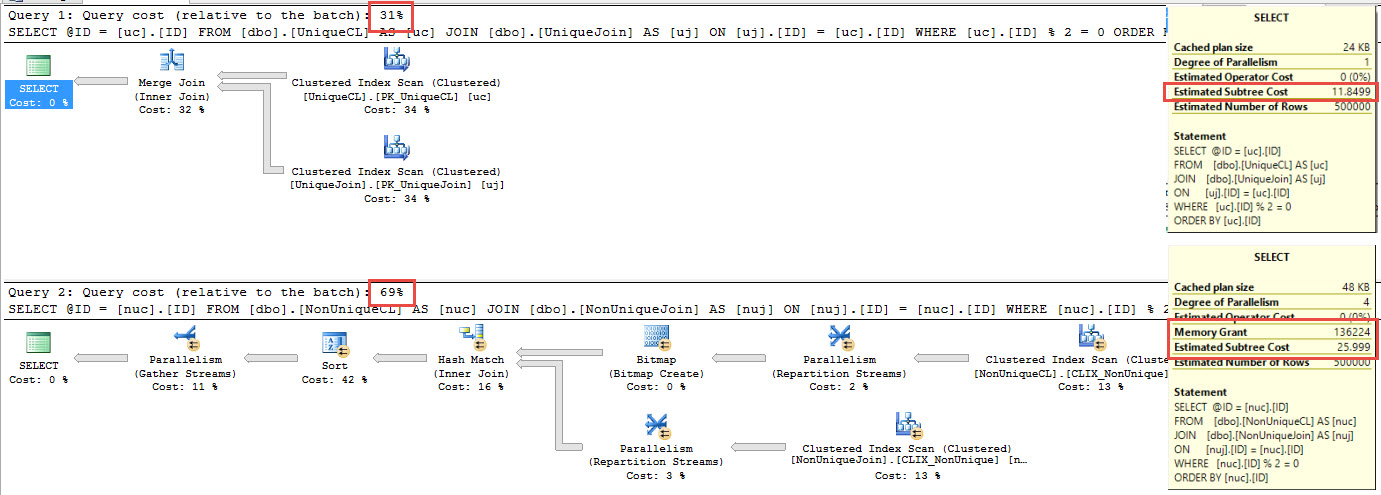
Not only does the query for the unique indexes choose a much nicer merge join, it doesn’t even get considered for parallelilzazation going parallel. The batch cost is about 1/3, and the sort is fully supported.
The query against non-unique tables requires a sizable memory grant, to boot.
Looking at the STATISTICS TIME and IO output, there’s not much difference in logical reads, but you see the non-unique index used all four cores available on my laptop (4 scans, 1 coordinator thread), and there’s a worktable and workfile for the hash join. Overall CPU time is much higher, though there’s only ever about 100ms difference in elapsed time over a number of consecutive runs.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
Table 'UniqueJoin'. Scan count 1, logical reads 3969, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. Table 'UniqueCL'. Scan count 1, logical reads 3968, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. SQL Server Execution Times: CPU time = 266 ms, elapsed time = 264 ms. Table 'NonUniqueCL'. Scan count 5, logical reads 4264, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. Table 'NonUniqueJoin'. Scan count 5, logical reads 4264, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. Table 'Workfile'. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. Table 'Worktable'. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. SQL Server Execution Times: CPU time = 1186 ms, elapsed time = 353 ms. |
Fair fight
So, obviously going parallel threw some funk on the floor. If we force a MAXDOP of one to the non-unique query, what happens?

Yep. Same thing, just single threaded this time. The plan looks a little nicer, sure, but now the non-unique part is up to 85% of the batch cost, from, you know, that other number. You’re not gonna make me say it. This is a family-friendly blog.
Going back to TIME and IO, the only noticeable change is in CPU time for the non-unique query. Still needed a memory grant, still has an expensive sort.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
Table 'UniqueJoin'. Scan count 1, logical reads 3969, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. Table 'UniqueCL'. Scan count 1, logical reads 3968, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. SQL Server Execution Times: CPU time = 265 ms, elapsed time = 264 ms. Table 'Workfile'. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. Table 'Worktable'. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. Table 'NonUniqueJoin'. Scan count 1, logical reads 4218, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. Table 'NonUniqueCL'. Scan count 1, logical reads 4218, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. SQL Server Execution Times: CPU time = 766 ms, elapsed time = 807 ms. |
Just one index
The nice thing is that a little uniqueness goes a long way. If we join the unique table to the non-unique join table, we end up with nearly identical plans.
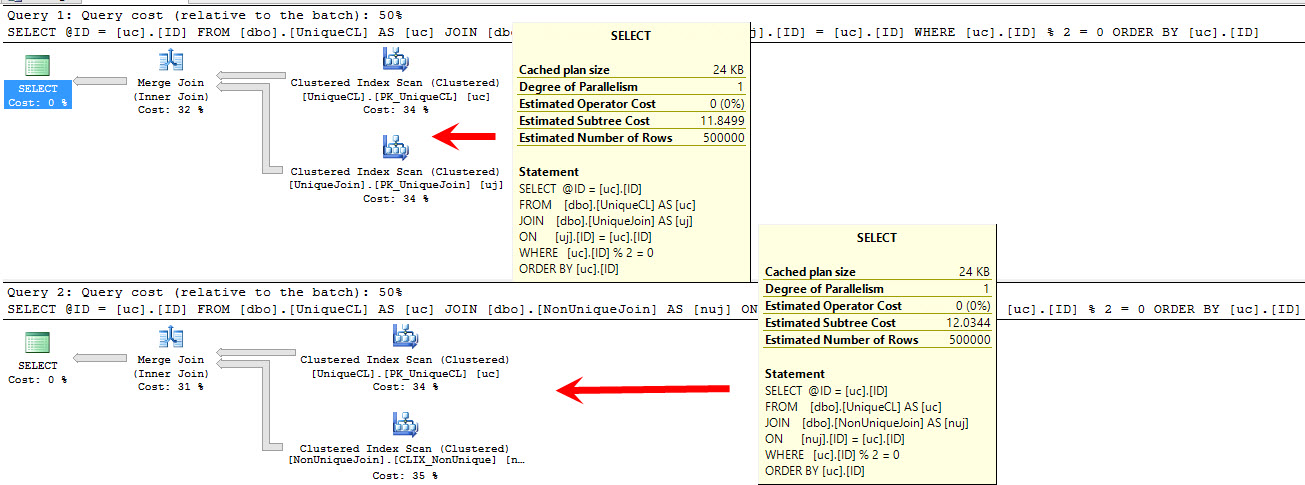
|
1 2 3 4 5 6 7 8 9 10 11 |
Table 'UniqueJoin'. Scan count 1, logical reads 3969, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. Table 'UniqueCL'. Scan count 1, logical reads 3968, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. SQL Server Execution Times: CPU time = 265 ms, elapsed time = 267 ms. Table 'NonUniqueJoin'. Scan count 1, logical reads 4218, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. Table 'UniqueCL'. Scan count 1, logical reads 3968, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. SQL Server Execution Times: CPU time = 266 ms, elapsed time = 263 ms. |
Done and doner
So, you made it to the end. Congratulations. I hope your boss didn’t walk by too many times.
By the way, the year is 2050, the Cubs still haven’t won the world series, and a horrible race of extraterrestrials have taken over the Earth and are using humans as workers to mine gold. Wait, no, that’s something else.
But! Hey! Brains! You have more of them now, if any of this was enlightening to you. If you spaced out and just realized the page stopped scrolling, here’s a recap:
- Unique indexes: SQL likes’em
- You will generally see better plans when the optimizer isn’t concerned with duplicate values
- There’s not a ton of downside to using them where possible
- Even one unique index can make a lot of difference, when joined with a non-unique index.
As an aside, this was all tested on SQL Server 2014. An exercise for Dear Reader; if you have SQL Server 2012, look at the tempdb spills that occur on the sort and hash operations for the non-unique indexes. I’m not including them here because it’s a bit of a detour. It’s probably not the most compelling reason to upgrade, but it’s something to consider — tempdb is way less eager to write to disk these days!
Thanks for reading!
Brent says: I always wanted proof that unique clustered indexes made for better execution plans!

29 Comments. Leave new
+1 TF2 humor!
+1 Willy Wonka humour!
Also, your article has bizarrely popped up here too: http://www.tuicool.com/articles/faaMBfz
+1 Willy Wonka reference…
Great article.
Is this only a factor if the data in the index is “naturally” unique; or will it also affect indexes if using the the ‘make my index unique’ unique flag when creating indexes?
Hi! Which flag is it that you’re talking about?
Sorry – mixed two things together … just ignore me.
It was more in line with John’s question further down, but wrote it too much in a hurry so mixed things together 😀
I am really enjoying your posts – keep them (and the Willy Wonka references) coming!
So… if I understand this correctly, are you suggesting that if we have, for example, a Clustered Index on a surrogate key in a Data Warehouse environment, which we know the Surrogate Key should always be unique since it’s an IDENTITY column, if we make it a Unique Clustered Index (still on the Surrogate Key) it will [generally] perform better than the non-unique Clustered Index on the same column?
If you’re not using the column to do anything (join, filter, order), then perhaps not. In my examples, the unique column was being actively used for query operations.
Solid point, thanks!
…”used all four cores available on my laptop (4 scans, 1 coordinator thread)”.
I don’t see it at all.
I thought that ‘Scan’ counted the number of times the object was scanned.
Am I having a bad reading day?
STATISTICS IO, for parallel plans, counts things strangely. For simplicity, each core got a thread (1-4). Each thread scanned the object once. So four scans. Then there’s a coordinator thread (0) that gathers rows from each scan. So it counts five, because SQL spawned a thread to manage parallelism.
How about unique non-clustered indexes?
Same deal with those. Using these tables, you can add the clustered indexes as nonclustered indexes instead, and see the same patterns emerge.
To be complete (tested it just now):
It works the same way if you create a UNIQUE CLUSTERED INDEX instead of the PK.
The comparison between execution plans when I run the initial two SELECTs are identicial the only way I can get the Unique Table to use a Merge Join is to add a HINT of MAXDOP 1.
It this potentially identicating that the configuration of my server settings are incorrect?
Ha, saw the TF2 humor and had to do a double take.
The downside seems to be that “UNIQUE” on large tables often doubles the initial index creation time.
It can, sure. I think it depends a bit on the data you’re indexing, and how cool your server is. Sometimes sorting in tempdb helps a bit as well.
Please edit “2050, the Cubs still haven’t won the world series” this is incorrect 🙂
This is the internet. You can’t just edit the internet.
Hi Erik,
What about the known impact of UNIQUE index on CDC operation codes?
When index is unique and any of its key columns is in the list of tracked columns on e.g. MyCdcTable_CT table, then SQL engine creates so called deferred updates (stated as normal behavior), which are reported as DELETE(1) and INSERT(2) operations vs. an UPDATE(3 & 4) operation on the CDC side.
Sources:
https://social.msdn.microsoft.com/Forums/sqlserver/en-US/72b37e54-c22a-4cf9-8997-69372f17f75c/cdc-operation-giving-wrong-result?forum=sqldatabaseengine
https://support.microsoft.com/en-us/kb/238254
That means, if you have CDC enabled, say good bye to UNIQUE indexes.
Is that correct or there is still a workaround for base table (not the …._CT one) level updates?
Thank you.
Yuri — so, you’re suggesting that people not use Primary Keys if they’re using CDC? Or unique clustered indexes? Those can result in the split/sort/collapse behavior of the deferred update that you’re talking about, as well.
As far as fixes and workarounds go, I’m not sure. I don’t work with CDC often (if at all), and don’t keep up to date on it. The KB article you posted is very old, but the forum post is very new. It looks like an ongoing issue, I guess.
Thanks!
Erik,
thank you for your reply.
There is no workaround provided/suggested by MS or SQL forums at this point.
While the impact of deleted/updated PK’s key value(s) is unlikely, under normal circumstances, UNIQUE clustered and non-clustered indexes impact the BI side of data load process on the DWH server (in our case at least).
There is a KB #302341(Last Review: 12/06/2015 03:30:31), which is not that old, it suggests to use trace flag 8207. Unfortunately that flag works only for a single row update (aka a singleton update).
So, the possible solution could be either create a scheduled jobs which fixes those 1 and 2 codes to 3 and 4 accordingly (this could be a time/resource sensitive/expensive process though) or to have the BI side data load process to be deferred update case aware, so to speak, and analyze the existence of those updated keys values (like being really DELETED and/or INSERTED) against base table(s) accordingly to avoid a confusion caused by reported CDC operation codes.
Thank you.
Heh. You should see some of the Primary Keys people choose out there 😉
You may have already read the CDC performance tuning white paper from MS, but just in case anyone stumbles across this who hasn’t, it may be worth a read: https://msdn.microsoft.com/en-us/library/dd266396%28v=sql.100%29.aspx?f=255&MSPPError=-2147217396
Thank you for sharing your thoughts and the URL with community. 🙂
Erik/All, I know this is an older post, but I have an interesting situation with a vendor provided solution. Erik, you indicate that SQL Server loves unique indexes but this vendor solution seems to add (randomly in a lot of cases) unnecessary uniqueness by appending the PK (ID) column to the end of several indexes on any given table. Based on my understand of inserts/updates/deletes, I can’t imagine this is helping out. Can too many unique indexes on a table, trailing with the primary key column for uniqueness, have a negative performance impact?
Jon — if it’s mostly singleton inserts, probably not. If it’s large data loads, yes. If you want, post more details on http://dba.stackexchange.com
Thanks!
In our cases, I prefer to use not unique indexes. For instance we have a table with hundreds of millions keywords to be analyzed. The keyword is unique (clustered index & primary key). But as we cannot do them all at once, we have a priority column as well. So we create a not unique, non-clustered index with only the Priority column and the keyword as included column.
This gives the following performance advantages:
1. No additional constraint is checked when adding.
2. When inserting a keyword, any page which has free space left and containing the same priority entries can be used. Meaning less fragmentation, less maintenance (rebuild/reorganize) Note that we also delete from this table and priority is just a tinyint, so this happens in most cases.
I’m a little confused – are you saying you have a heap plus a nonclustered index, or a clustered index plus a nonclustered index? Or are you thinking that the nonclustered index is the only storage for the table? (It isn’t.)