
It’s not glamorous
And on your list of things that aren’t going fast enough, it’s probably pretty low. But you can get some pretty dramatic gains from indexes that cover columns you’re performing aggregations on.
We’ll take a quick walk down demo lane in a moment, using the Stack Overflow database.
Query outta nowhere!
|
1 2 3 4 5 6 7 8 |
SET NOCOUNT ON SET STATISTICS TIME, IO ON SELECT v.UserId, v.BountyAmount, SUM(v.BountyAmount) AS BountyTotal FROM dbo.Votes AS v WHERE v.BountyAmount IS NOT NULL GROUP BY v.UserId, v.BountyAmount; |

Zooming in a bit on the Hash Match, this is what it’s doing. It should look pretty familiar to you if you’ve ever seen a Hash Match used to JOIN columns. The only difference here is that the Hash table is built, scanned, and output. When used in a JOIN, a Probe is also built to match the Residual buckets, and then the results are output.
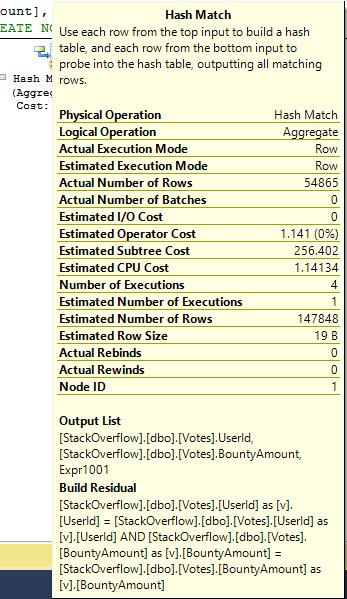
It took quite a bit of activity to do a pretty simple thing.
/*
Table 'Votes'. Scan count 5, logical reads 315406, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'Worktable'. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'Workfile'. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
SQL Server Execution Times:
CPU time = 3609 ms, elapsed time = 1136 ms.
*/
Since this query is simple, our index is simple.
|
1 |
CREATE NONCLUSTERED INDEX IX_GRPBY ON dbo.Votes ( BountyAmount, UserId ); |
I’m using the BountyAmount column in the first position because we’re also filtering on it in the query. We don’t really care about the SUM of all NULLs.
Taking that new index out for a spin, what do we end up with?

The Hash Match Aggregate has been replaced with a Stream Aggregate, and the Scan of the Clustered Index has been replaced with a Seek of the Non-Clustered Index. This all took significantly less work:
/*
Table 'Votes'. Scan count 1, logical reads 335, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
SQL Server Execution Times:
CPU time = 0 ms, elapsed time = 278 ms.
*/
Zooming in on the Stream Aggregate operator, because we gave the Hash Match so much attention. Good behavior should be rewarded.

Filters, filters, filters
If we want to take it a step further, we can filter the index to avoid the NULLs all together.
|
1 2 3 4 |
CREATE NONCLUSTERED INDEX IX_GRPBY ON dbo.Votes ( BountyAmount, UserId ) WHERE BountyAmount IS NOT NULL WITH ( DROP_EXISTING = ON ); |
This results in very slightly reduced CPU and IO. The real advantage of filtering the index here is that it takes up nearly 2 GB less space than without the filter. Collect two drinks from your SAN admin.
/*
Table 'Votes'. Scan count 1, logical reads 333, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
SQL Server Execution Times:
CPU time = 0 ms, elapsed time = 233 ms.
*/
And, because I knew you’d ask, I did try making the same index with the column order reversed. It was not more efficient, because it ended up doing a Scan of the Non-Clustered Index instead, which results in a bit more CPU time.

9 Comments. Leave new
“And, because I knew you’d ask, I did try making the same index with the column order reversed. It was not more efficient, because it ended up doing a Scan of the Non-Clustered Index instead, which results in a bit more CPU time.”
Interesting!
Regarding this last point, was the column order reversed both before and after the index filter was applied? Would a scan of the NCIX matter as much in the case of the filtered index?
@TonyM, I think that the comment about reversing the column order applies to the non-filtered version of the index. With the filtered version of the index, a scan is the optimal choice because all of the rows that match the filter match the query. Therefore, the index order is not going to create a seek in this case. I confirmed on my copy of StackOverflow that the scan is used regardless of the index order and that we get the exact same query plan and estimated cost in each case.
But for the non-filtered version, seeking on BountyAmount allows the huge number of rows with a NULL BountyAmount to be avoided. Therefore, the index order that leads with BountyAmount is a good choice in this case.
Thanks for confirming. That’s what I was thinking – in the filtered index the column order shouldn’t matter because it’d probably give the same plan in either case.
Thanks for this write up.
I test it on the dba.stackoverflow database.
Went from:
/*
Table ‘Votes’. Scan count 1, logical reads 1123, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
SQL Server Execution Times:
CPU time = 47 ms, elapsed time = 116 ms.
*/
To
/*
Table ‘Votes’. Scan count 1, logical reads 4, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
SQL Server Execution Times:
CPU time = 0 ms, elapsed time = 33 ms.
*/
“I’m using the BountyAmount column in the first position because we’re also filtering on it in the query.”
I think the index you’ve created works specifically for the WHERE clause filter and is of no use to the GROUP BY clause. The fact that UserID is a key in the index is only useful because it’s included and prevents a key-lookup. I would suspect you’d get the same results with an index like:
CREATE NONCLUSTERED INDEX [IX:BountyAmount -Inc] ON dbo.[Votes] (
[BountyAmount]
)
INCLUDE (
[UserId]
)
WHERE (
[BountyAmount] IS NOT NULL
)
Thumbs Up 🙂
My execution plan shows a hash match (partial aggregate) instead of a stream aggregate even though I have a non-clustered index (which basically means sorting is already in place). It gives me a suggestion to create another non-clustered index. How do I convert it into a stream aggregate?
AK — for questions, head over to http://dba.stackexchange.com
I have posted my question on http://dba.stackexchange.com. Thanks!