
With SQL Server AlwaysOn Availability Groups, you can offload backups to a replica rather than running them on the primary. Here’s how to do it:
1. Install Ola Hallengren’s utility scripts on all of the replicas. During the install, it creates a laundry list of SQL Agent jobs, but doesn’t set up schedules for any of them. More on that in a couple of steps.
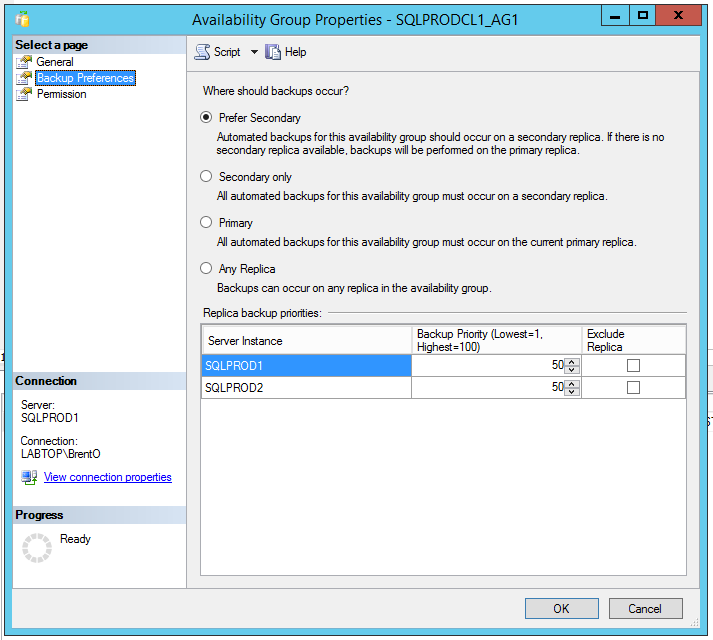
2. Set your backup preferences. In SSMS, right-click on your Availability Group, click Properties, and click the Backup Preferences pane.
The first option, “Prefer Secondary,” means that your backups will be taken on a secondary server unless all secondaries go offline, at which point they’ll be taken on the primary. There’s some risk here: if communication falls behind, your secondary may be running backups of old data, as Anthony Nocentino explains. In that case, you won’t get backup failure alerts, but you won’t be able to meet your RPO. Monitoring for that is an exercise left for the reader.
In the “Replica backup priorities” window, rank your replicas to choose who will do the backups first.
Say I have three servers – two in my primary data center, and one in my disaster recovery site. I’d rather have my full backups running in my primary data center because if I need to do a restore, I want the backups nearby. (You can also run backups in both places – and I would – but more on that in a future post.)
To configure that, I’d set priorities as:
- SQLPROD1 and SQLPROD2 (my primary data center replicas) – both 50 priority
- SQLDR1 (my disaster recovery replica) – priority 40
3. Test your backup preferences. Run this query on each replica:
|
1 2 3 |
SELECT d.database_name, sys.fn_hadr_backup_is_preferred_replica (d.database_name) AS IsPreferredBackupReplicaNow FROM sys.availability_databases_cluster d |
This returns a list of databases in an AG, and whether or not they’re the preferred backup replica right now. Check that on all of your replicas to make sure backups are going to run where you expect, and if not, revisit your backup preferences in the last step.
4. Configure Ola’s Agent full backup jobs. On any replica, in the Agent job list, right-click on the “DatabaseBackup – USER_DATABASES – FULL” job, click Properties, click Steps, and edit the first step. By default, it looks like this:
sqlcmd -E -S $(ESCAPE_SQUOTE(SRVR)) -d master -Q “EXECUTE [dbo].[DatabaseBackup] @Databases = ‘USER_DATABASES’, @Directory = N’C:\Backup’, @BackupType = ‘FULL’, @Verify = ‘Y’, @CleanupTime = NULL, @CheckSum = ‘Y’, @LogToTable = ‘Y'” -b
You need to change these parts:
- @Directory – set this to your backup path. I like using a UNC path that all of the replicas can access.
- @Verify – I’d recommend turning this off to make your backup jobs go faster. If you really want to verify your backups, restore them on another server.
- If you want to run the backups on a secondary replica rather than the primary, add a parameter for @CopyOnly=’Y’
- If you only want to back up specific databases, modify the @Databases parameter. I don’t like doing that – I’d rather have one job for all of my backups. The way this is set now (USER_DATABASES), this one job will back up all of my databases that aren’t in an AG, plus it’ll back up the AG-contained databases where this replica is the preferred backup right now.
With AlwaysOn AGs, replicas can only run copy-only backups, and people often think that’s a problem. It’s only a problem if you want to use differential backups – otherwise, with AGs, it doesn’t affect transaction log handling at all. I don’t recommend using differentials with AlwaysOn AGs, but if you insist on doing it, you’ll be running your full backups on your primary replica.
Other parameters you may want to set:
- @CleanupTime – how many hours of backup files you want to keep around
- @Compress – Ola inherits the default compression setting at the server level, but you can hard code this to Y if you want to make sure backups are always compressed
So here’s what my Agent job script ends up looking like, with my changed parts in bold:
sqlcmd -E -S $(ESCAPE_SQUOTE(SRVR)) -d master -Q “EXECUTE [dbo].[DatabaseBackup] @Databases = ‘USER_DATABASES’, @Directory = N’\\FILESERVER1\SQLBackups’, @CopyOnly=’Y’, @CleanupTime=48, @Compress=’Y’, @BackupType = ‘FULL’, @Verify = ‘N’, @CleanupTime = NULL, @CheckSum = ‘Y’, @LogToTable = ‘Y'” -b
5. Copy these changes to all replicas and test the full jobs. Make sure each replica that isn’t supposed to run the fulls, doesn’t, and the replica that IS supposed to run the fulls, DOES. In really mission-critical environments where we’re building the new AG servers from the ground up, we actually fail the AG around to different servers to test behavior when different servers are the primary – and when entire data centers go down.
6. Repeat the setup with your log backup jobs. Right-click on the “DatabaseBackup – USER_DATABASES – LOG” job and click Properties, Steps, and edit the first step. Set the @Directory and @Verify steps as we did earlier.
Here’s where things get a little tricky – you don’t have to add @CopyOnly=’Y’ for the log backup steps. There’s no such thing as a copy-only log backup in an Availability Group secondary, much to my dismay.
You might also consider setting the @ChangeBackupType parameter to Y. By default, if Ola can’t do a transaction log backup (like if it’s a brand new database that has never had a full backup before), then the log backup is skipped. If you set @ChangeBackupType=’Y’, then Ola will do a full backup in that situation, and then do a log backup. However, if it’s a large database, this might take a while to perform the full, and this will tie up your log backup job while it runs. Say the full takes 20 minutes to perform – this might blow your RPO/RTO commitments.
7. Copy these changes to all replicas and test the jobs. Same thing here that we did with the full backups.
8. Configure your DBCC CHECKDB jobs. You need to check for corruption on any server where you’re running backups – here’s why.
9. Design your monitoring. Sadly, SQL Server doesn’t centralize backup history, so it’s up to you to poll all of your replicas to find out where backups are happening for any given Availability Group. In one case, I had a DBA change the backup preferences and Ola’s job settings incorrectly, and all of the backup jobs were succeeding – but none of them were backing up one of his Availability Groups.
10. Set yourself a weekly reminder to test restores. AG backups are notoriously complex, and if you cared enough to set up this whole expensive infrastructure, then you should care enough to test it. Make sure you have a good, restorable set of backups.
Kendra says: In a complex environment, I’m a fan of some paid third party tools that help you control the compression on your backups and which can keep a central repository of backup history, to help you monitor. Good news: Ola’s solution integrates with them! You can have your backup cake and eat it, too.

90 Comments. Leave new
Nice solution. Have this setup alredy on place with Olas backups scripts and can add one comment. It is worth to have below T-SQL as first step of every backup job on every node:
Similar solution is also working also nice for Olas index maintenance scripts
if (
select role_desc from sys.dm_hadr_availability_replica_states
inner join sys.dm_hadr_name_id_map
on sys.dm_hadr_availability_replica_states.group_id = sys.dm_hadr_name_id_map.ag_id
where sys.dm_hadr_name_id_map.ag_name = ‘YOUR_AG’ and is_local = 1
) = ‘secondary’
begin
PRINT(‘This is secondary replica and you can go to next step.’);
end
else
begin
RAISERROR(‘This is primary replica. Do not countinue this job.’, 11, 1);
End
Jakub – Yeah, of course this assumes you only want to run backups on a secondary – which can be a little dangerous too. You can end up running backups on multiple secondaries, or running one on an out-of-date secondary with broken replication. May want to build in a few more checks there. I love the idea though!
We started off using a step to check if the current replica was the active as well, but have switched to not use that approach. That said, I thought i would share a function that you can use which support distributed availability groups as well. Of course you need to be on SQL 2016 or above.
CREATE FUNCTION [dbo].[fn_hadr_group_is_primary] (@AGName sysname)
RETURNS bit
AS
BEGIN;
DECLARE @PrimaryReplica sysname;
DECLARE @IsDistributed bit = 0;
select @IsDistributed = is_distributed
from sys.availability_groups ag
WHERE ag.name = @AGName;
if @IsDistributed = 0
BEGIN
SELECT
@PrimaryReplica = hags.primary_replica
FROM sys.dm_hadr_availability_group_states hags
INNER JOIN sys.availability_groups ag ON ag.group_id = hags.group_id
WHERE ag.name = @AGName;
IF UPPER(@PrimaryReplica) = UPPER(@@SERVERNAME)
RETURN 1; — primary
END
else
BEGIN
SELECT
@PrimaryReplica = hags.primary_replica
FROM sys.dm_hadr_availability_group_states hagsd
INNER JOIN sys.availability_groups agd ON agd.group_id = hagsd.group_id
INNER JOIN sys.availability_groups ag on hagsd.primary_replica = ag.name
inner join sys.dm_hadr_availability_group_states hags on ag.group_id = hags.group_id
WHERE agd.name = @AGName;
IF UPPER(@PrimaryReplica) = UPPER(@@SERVERNAME)
RETURN 1; — primary
END
RETURN 0; — not primary
END;
GO
This was perfect timing. We use the ola script and I was just sitting down to research the secondary backup via the script to make sure our 2014 AG is backing up correctly. Just tested it on 3 node setup with 2 different AG groups, one on node 1 and another on node 3, using node 2 for backups. Really digging the new features in MSSQL.
Saved me a ton a time. Much appreciated. Glad I signed up for your newsletter.
If you’re backing up transaction logs frequently (say, every 60 seconds), the @CleanupTime parameter can incur a lot of wait and churn pruning backups. Consider a separate job (maybe daily or weekly) that does the pruning.
If you have multiple secondaries and want to make sure one of them is preferred over the other for backups, make sure the backup priority is set. The system function that Ola’s script relies on will choose the replica that is alphabetically first if all other things are equal.
Thank you , this helped me a lot determining why certain backup happen on only one of my 2 secondaries and not the other.
Very nice explanation Brent…But I’ve one Quick Question.
We are using this solution for our Availability Groups(2 Replicas) without specifying “@CopyOnly=’Y’” explicitly and we’ve set “Prefer Secondary” for Backup preferences. I don’t see any issues in our environment. My understanding is by default if the databases are part of an AG, using Ola’s solution Copy-only full backups and transaction log backups are performed on the preferred replica(per our preference) even without specifying CopyOnly=’Y’ in our Jobs.
Can you share your thoughts on this and please correct me if am wrong…
Sreekanth – rather than asking me, why not check? Dig into your MSDB backup history tables and see what’s going on. It’s best if you gain confidence for yourself in how your solutions are working.
We use Ola Hallengrens scripts on our AlwaysOn replicas and they work quite well.
One problem that we ran into: We set up a custom Full backup job on the Secondary servers with the @CopyOnly=Y set. Then one of the DBAs copied the script for the job to use for the Transaction Log backups. He changed the file path for the log backups but left the @CopyOnly set to Y. The log backup job ran successfully but never truncated the log after backup.
We were constantly having to add space to our log volumes because they kept growing. It took an entire week to track down why our log files were continuing to grow. The SAN team was not happy with having to add space every few days.
This was the only problem we have ever had with Ola’s script. I would recommend them above the built-in Maintenance Plans.
Why don’t you recommend using differential backups with AlwaysON AGs?
Morten – they’re not supported on the secondaries.
Yes Brent, I know that 🙂
But i’m guesting that since you don’t recommend using diff, you also don’t recommend taking backup on the primary replica. And why is that?
Is it only due to performance or is there some other reason why?
Morten – oh no, I’m okay with people taking backups on the primary. It all comes down to what you want to use AGs for – some people prefer to offload the backups to a secondary, some people don’t. I love how AGs give you the flexibility to make those decisions based on what your business needs.
Hi Brent,
I’d like some follow up on Morten’s question. I understand that full and diff backups are not supported on secondaries and I understand that AG’s give you this flexibility. However, you stated in #4 that you don’t recommend doing differentials but you haven’t answered Morton’s questions as to why you don’t. Why not? Do you prefer offloading the backups off of prod for performance or is there another reason? We are setting up some AGs and plan on doing full/diffs on the primary and would like to know why you prefer not to do diffs. We prefer diffs because we run T-Log backups every 10 minutes and I don’t want to have to restore a lot of log files in case of disaster.
I’d also like to know why you wouldn’t run verify against backups. Is it just a speed factor?
Thanks!
Phillip – personalized backup and recovery planning is a little outside of the scope of what I can do in a blog comment.
One quick note – when you say “I don’t want to have to restore a lot of log files in case of disaster” – isn’t that what you have an Availability Group for?
SQL Server does not have good backup solution for Always on Availability Group
I think you have a error in the sqlcmd script at the end of step 4. Looks like you assign a value to the @CleanUpTime parameter twice. Trivial I know but it might help someone who copies the script or I might be missing something.
Hi Brent
Thanks for the article. I’m a newbie in the world of AlwaysOn and using the script from Hallengren. So. brought the facts on the table 🙂
I followed your steps and it is working as expected, with one exception.
I’m just wondering about the parameter setting for LogToTable. You set them to ‘Y’. But from my point of view, this is not correct when running on the SECONDARY (preferred) as the database is read only.
Or did I missed a point?
regards
fabian
Fabian – the LogToTable parameter points to a table that typically lives in the master database. It doesn’t live in the database you’re backing up. Hope that helps!
Hi Brent
Ah okay. I created a separate database to hold the table and procedure and therefore it fails.
Your setup with master make then sense.
Thanks
Regards
Fabian
Hi Brent,
Little late to the party, but hope you still read this thread.
Like Fabian, we have always had Olas solution in a separate database, not master. Is the use of Availability Groups a case where that setup does not work? Should we reinstall Olas solution to master and change all the jobs, or is there some way to come around this using a separate database? (One possible solution I am thinking about, is to keep this Ola-database out of the AG and just create another version of it on the DR-server, but not sure if this would interfere with any of the built in AG-stuff?)
Any insights on this is appreciated.
Gert – for Q&A, head on over to a Q&A site like https://dba.stackexchange.com.
I thought, it’s required license, backing up on Secondary node.
This is also very tricky.
Hi Brent,
Greetings !!
When we configure backups on secondary replica (synchronous commit) where only COPY_ONLY backup is allowed. Once we setup a backup maintenance plan on secondary – is something tricky.
My question is –
1) Why does it generates .trn files though I SELECT COPY_ONLY full backup?
2) How do we manage with COPY_ONLY backups in case of disasters ?
My queries could be silly, please clarify if possible.
Regards,
Srikanth
Srikanth – blog post comments aren’t really an open question-and-answer forum. Check out http://dba.stackexchange.com.
Brent – never mind, I was curious to know from you. Anyhow thanks for the quick response.
I thought Always On’s log-based replication was unidirectional (primary –> secondary). If you run your transaction log backups on a secondary replica, how does that truncate the log back on the primary replica? Is there a mechanism that handles this automatically?
Chuck – the secondaries can still talk to the primary to note which LSNs have been backed up.
Hi Brent,
I followed your instructions to a tee in an AlwaysOn two-node environment, which was already taking full, diff and t-log backups on the primary use ola’s backup jobs.
1. Disabled the DIFF job.
2. Backup preferences – Prefer Secondary with backup priority 50:50. (I assume with a 2 node cluster this is the best setup).
3. Changed the ‘Copy-Only’ option in the full backup job to Y.
4. Added in the @ChangeBackupType param and set it to Y.
Initially the log backups were taken for each database in the AG until the first scheduled copy only full backup which was taken on the secondary as expected. From viewing the root backup location the log backups are taken for each database outside the AG and stored in folders named after the node they were taken on, as expected. In the folder named created for the AG group there’s no logs after the time of the first copy only backup.
I took a sample of job outputs from the log jobs history on both node .i.e before any changes from each node, after I made the changes, after the scheduled copy_only backup, compared these stepping through with the search term ‘BACKUP LOG’ expecting to see a conclusive pattern to match what I was seeing in the backup filer but even in the case where nothing was changed not every LOG BACKUP was recorded here.
I took a second stab at this by reverting all the changes, taking a regular full backup from the primary, waiting a while for a few scheduled log backups, then changing the backup preferences to preferred secondary and scheduling a copy_only full backup. This time once I changed the backup preferences it stopped taking log backups even before the copy_only full backup.
I have searched the root of the filer for the missing logs in case they were written to an unusual location but to no avail.
Is there anything obvious (or not so obvious 🙂 ) that I could be doing wrong? Any pointers would be much appreciated 🙂
Thank!!
Chris
Chris – sorry, my eyes are kinda glazing over here. This is waaaay too long of a question to post in someone’s blog as a comment. When you’ve got a multi-paragraph question, head on over to http://dba.stackexchange.com where thousands of folks are ready to help with various questions. Good luck!
Sorry Brent. That explanation kind of ran away from me 🙂 Thanks for the pointer!
Hi Brent
One question about fn_hadr_backup_is_preferred_replica, I’ve noticed that based on permissions this function returns wrong values. If I query this using sysadmin credentials, this returns 1, using just public and VIEW SERVER STATE permissions this returns 0. I’ve double checked lower and uppercase and if I am connected to the correct server, but did not find a solution. Are there really sysadmin permissions needed just to query this?
Thanks in advance
Christian – for questions, check out Dba.stackexchange.com.
Hi,
I have 2 servers in the High Availability implementation. One is primary and one is secondary. Backup Preference is set to Prefer Secondary. If the scripts are installed on both servers where does the schedule get created?
Kim – you build the schedule on both servers.
Just finished my version of a Automated Restore script against Ola Hallengrens backup script. please contribute if you can.
https://github.com/GregWhiteDBA/MSSQLAutoRestore
Late to the party but I am a little fuzzy on how the backup with copy only will work? If you do a backup with COPY_ONLY doesn’t it essentially fall in line with the original LSN chain from the full backup. If i am backing up with copy only and doing log backups how do I restore them to the point in time if none of the copy only backups are the start of a chain and the intial full no longer exsist?
I have been using Ola’s scripts with AG’s and copy only backups. I may be wrong but the copy only backups dont affect the log chain. I treat these like normal full backups combined with usual log backups that do give point in time restore capability.
OK so basically just maintain enough logs and full copy only backups to restore to where you need to get to. I keep 3 days of full copy only and 3 days of logs. I need to test the restore in the lab and just make sure it works as expected.
Yup, developed an automated restore script for olas default backup folder structure if interested let me know, been using it to test restores and capture restore times
The bad thing about this article is that I followed it, completed my task of setting up Ola’s scripts for our newest server (our first with AGs), and it worked perfectly. I fear I’ve set an unrealistic expectation of rapid turnaround and perfection now, that I’ll never be able to live up to!
> With AlwaysOn AGs, replicas can only run copy-only backups, and people often think that’s a problem.
When you say ‘replicas’, do you mean both the primary replica and the secondary replica, OR just the 1 or more secondary replicas?
Troy.
#
Troy – that refers to secondary replicas.
Hi I’m junior DBA and we are about to implement Always On SQL server 2016 I’m trying to understand how can i backup full- copy only on secondary replica and after the full copy only backup with log backup with no copy only whats the solution for transaction log backup in a an always on environment
As long as you have the backup preferences set withing the availability group setup then Ola’s backup scripts should take care of the database and transaction log backups. I back mine up to a central network share so i have one place to go for all my AG backups
Heoo
SQL Server does not have Good backup solution for Always on Availability Group
Matt – can you elaborate on that?
right? look at all the questions here, it’s like Ola’s script is a crutch in this industry and IT pro’s just slap it on a server when a Maintenance Plan should be all you need. I guess MS thinks the same since there’s extra support out of the can for AG. When your AG swaps your primary over to a replica and now all your backup jobs are failing, what do? go ask on stackexchange.
edit to above comment: I guess MS thinks the same since there’s NO extra support out of the can for AG
Hi Brent,
Thanks for the Post:) Where would you recommend to run Ola’s script for backup of System databases please, We are running System Database backup on secondary only at the moment?
Sajid – you’re welcome. I like backing up all of my servers’ system databases. I don’t usually restore them, but sometimes it comes in handy when someone accidentally deploys a table into the master database, and then the server goes down later.
I have a couple of questions on this. Let’s assume I’m using the Prefer Secondary option to offload backups to secondary.
– Am I able to do a point in time restore from the backups on the secondary?
– By combining copy only fulls and transaction backups
– Can I disable all backups on the primary?
– And won’t the log files keep growing if this is done?
Janneaa:
– Am I able to do a point in time restore from the backups on the secondary? – Yes
– By combining copy only fulls and transaction backups – Yes
– Can I disable all backups on the primary? – No, users can still run backups anywhere they want manually
– And won’t the log files keep growing if this is done? – Can you be more specific about what “this” is?
Here’s what I meant by the last two questions:
– Is it okay to stop taking scheduled backups from the primary (since the goal is to offload them to secondary)?
– If the scheduled backups were disabled on primary then obviously transaction logs would keep growing. Could this be solved by taking only scheduled log backups on primary?
Janneaa – gotcha. Sure, you can take log backups from any replica, and they act just like log backups on the primary.
Hi Brent,
Thanks for the article! Great info. One question:
As stated in Ola’s scripts doco.
“DatabaseBackup has been designed not to delete transaction log backups that are newer than the most recent full or differential backup. This could explain why transaction log backups are not being deleted”.
So that means that taking COPY_ONLY backups only on the replica wont allow the Cleanup functions of the Transaction Log backups to fire and delete old logs yeah?
I’m currently setting up an AG cluster and have run into this exact problem (which is why i ask..) and have log backups that are not being removed after 24 hours as i’ve set it.
COPY_ONLY backups run each night on the replica only.
Does this mean you need to to run a FULL backup that is not copy_only somehwhere to allow the log backups to be cleaned up?
Luke 🙂
Hmm. hold up.
Think i found the problem. The drive had run out of space for the the full copy_only backup and that was holding the log backups back.
Nothing to see here…
(???)
I think something has changed since this post was put together. This post is a couple of years old now. I do know that Ola has made changes to his script and has new parameters related to AG.
I run
SELECT d.database_name,
sys.fn_hadr_backup_is_preferred_replica (d.database_name) AS IsPreferredBackupReplicaNow
FROM sys.availability_databases_cluster d
and machine TST01 is o and TST02 is 1, so TST02 is the preferred backup replica.
When I run the job on TST01 with the below the full backup of a database not in an AG (DBAUtility) happens against TST01, which is the primary, and not TST02, which is the secondary. Also, I have one database in an AG and it doesn’t get backed up anywhere. I can see that because when I query msdb I get an entry for DBAUtility on TST01 that a full backup has occurred there and not on TST02.
sqlcmd -E -S $(ESCAPE_SQUOTE(SRVR)) -d master -Q “EXECUTE [dbo].[DatabaseBackup] @Databases = ‘User_Databases’, @CopyOnly = ‘Y’,@Directory = N’C:\MyDirectory\’, @BackupType = ‘FULL’, @Verify = ‘Y’, @CleanupTime = 168, @CheckSum = ‘Y’, @LogToTable = ‘Y'” -b
I can post questions about this over on dba.stackexchange.com or email Ola Hallengren. I’m just not seeing this work the way the post describes.
Sure, for questions, feel free to do what you described there. Thanks!
i had this its because you need to run a full non copy only backup on all the AG databases first then the secondary sees you have done a full backup and will allow you to do copy only backups… hope that makes sense.
is it necessary to use @AvailabilityGroups parameter
Go ahead and read the documentation to see what that parameter does.
Thanks!
Thanks but again a bit confused will greatly appreciate if you can confirm the below based upon your one whether I can deploy the below to the replicas or simply the one you mentioned will work on all replicas as my back up preference is primary only
sqlcmd -E -S $(ESCAPE_SQUOTE(SRVR)) -d master -Q “EXECUTE [dbo].[DatabaseBackup] @Databases = ‘ALL_DATABASES, AVAILABILITY_GROUP_DATABASES ’, @Directory = N’\\FILESERVER1\SQLBackups’, @CopyOnly=’Y’, @CleanupTime=48, @Compress=’Y’, @BackupType = ‘FULL’, @Verify = ‘N’, @CleanupTime = NULL, @CheckSum = ‘Y’, @LogToTable = ‘Y’” -b
Hi,
Thanks for the post! I have been using Ola’s scripts with SQL 2014 AlwaysOn for 3 years now and they work great. I have a 3 node cluster on SQL 2014 and the Prefer Secondary option set, with all nodes having the backup priority 50. This always chooses only one secondary. However, on a 3 node AlwaysOn on SQL Server 2016, the same setup returns 1 for both secondaries when I query sys.fn_hadr_backup_is_preferred_replica. I couldn’t find documentation stating that something changed in the way this is meant to run. Did you ever encounter this issue?
Thanks!
For questions, head over to https://dba.stackexchange.com.
Hi Brent,
we have backup preference as primary and whenever the failover happens from Primary to secondary , The new primary which was secondary earlier does not have latest backups and so we receive the backup missing alerts on a daily basis.
Is there a solution for this ?
What is alerting you to the backups, I found there are table that record backups have happened but they are not the same across all the servers in your AGs. I.e if the backup happened on server 2 server 1 might not know about it. In order to check my backups I query all ag nodes and union then together.
But how do you query it? Is it linked servers ? For instance there are 300 servers so we can’t create linked servers across all 300. Is there a better way to achieve this ?
I created a SSIS solution that knows all the server names and loops through collecting backup info into a central table i can query. Its painful but doable.
Dear Brent,
Thanks for the detailed post, it helped a lot!
Though I think saying “you don’t have to add @CopyOnly=’Y’ for the log backup steps.” is a little bit misleading.
I lately had a chance to implement it on a 2 servers cluster with AO.
I thought that in case of a “prefer secondary” and CopyOnly=’Y’ marked, there’d be a case to generate a regular log backup instead, since copy only log backups fail in secondary replica.
Apparently, the job did copy-only log backup on the primary instead, the log file got full and the app crashed.
It was confusing since the full package creates 1 procedure and 2 jobs, knowing how well Ola deals with edge case, I though that the @CopyOnly=’Y’ should be marked in the procedure, and with the @BackupType=’L’ the script does the logic itself.
So, I’d put an emphasize on “DON’T add the @CopyOnly=’Y’ for log backups for prefer secondary”. Instead of “have to”.
Hi Brent, seems to be I am off late to put the question here seeing this post running from way back :). However, I will try :).
We have Always On setup between 2 VM’s ( 1 primary and 1 replica). we have our AG groups running on each server ( kind of active – active) to balance the load. In this scenario, how would I update the jobs so that it takes backups only from Primary Server?. Meaning, for some databases it should route to primary and take backups and for other databases it should route to replica to take backups. Intention is to take full and t-log backups only from Primary .
Gopikrishna – unfortunately I can’t do free personal consulting in the comments. Your best bet might be #SQLhelp on Twitter or in SQLslack: https://www.brentozar.com/go/sqlhelp
Guys, I have 2 questions:
1- where do you typically store the t-log and full backups when running on secondary replica? in a shared location? or do you leave on each server’s local folder. Thanks.
Great question. I always back up to a network share: https://www.brentozar.com/archive/2008/09/back-up-your-database-to-the-network-not-local-disk/
is there any SQL native backup solution via different network (use BAN network not use DATA network)? If we set BAN network on our AlwaysOn cluster can we able to use that network to backup with SQL native backup solution..
For general unrelated questions, head to a Q&A site like DBA.stackexchange.com or sqlservercentral.com.
Hi Brent.. I have been using the script to backup database to Azure Storage container. But, due to some reason, in one environment, It does not create backup files in the subfolders like [ServerName]\ [DatabaseName]\ FULL. Instead, all files are getting saved in default storage account location. Any ideas?
For general unrelated questions, head to a Q&A site like DBA.stackexchange.com or sqlservercentral.com.
Excuse me Sir!
VLDB need differential backup.
You’re excused.
hi brent, for the SQL AG db backup path, I’d like to use UNC so that backup can be put into a single place without worrying about fail over. If we put db backup to cluster node, backups (no matter which type ) may be scattered in more than one places if fail over event does happen, is this true?
Howdy – read this: https://www.brentozar.com/archive/2008/09/back-up-your-database-to-the-network-not-local-disk/
Why isn’t it feasible to for MS to allow a FULL or DIFF to be taken on a secondary and then push back the LSN point to the primary (out of band if you will) , its seems so “doable”. One of the reasons some of my customers will use alwayson, is because of RTOs and RPOs, but I am pretty sure most of the clients are like mine : the DBs are big, they highly OLTP type data (meaning this weeks data is often 1 week out 3 years added to the biggest tables). I dont want to store the other 155 weeks of data every night). And since they big, and since its OLTP : it would be great to offload backups if I could even for differentials (and especially for fulls)
In your dealing with MS, is the a conversation that comes up? Whats the primary thing holding that back.
I’m not sure what you mean – full backups have always been allowed on AG secondaries.
Differentials aren’t, but differential usage is fairly low. If that’s something that’s important to you, you would want to file a request on feedback.azure.com explaining why you need it.
Sure, I think you missed part “to push the LSN point to the primary”.
Sure you can run COPY_ONLY backups on a secondary, as many as you want, but it means that the LSN bit markers arent reset for differentials to be based on. That means your differential will just keep growing until you make a full backup on the primary. In otherwords, if you want to run differentials of any concern on a primary, you also need to run your fulls on that primary?
Ah, gotcha. I hear you – I don’t recommend diffs anyway – when you find yourself at that point, you’re better off doing storage snapshot backups instead. Restores take seconds, and diffs can’t even come close to that.
I have implemented Ola’s solution on a new AG Cluster.
Works as intended. Wonder why MS has not come up with some more support for taking backups of AG.
My still remaining issue is that on the primary the Dates of the last Backups are of course inaccurate ( why is that info not displayed in the AG ? ) .
I noticed this in the Article:
Kendra says: In a complex environment, I’m a fan of some paid third party tools that help you control the compression on your backups and which can keep a central repository of backup history, to help you monitor.
Which tool can combine the info of all the backups “spread” across ? the Info of the backups on the primary is apparently wrong and I need to gather the info manually by selecting the files from the share. Any possibility to update the Backup Info on the primary to reflect the actual backup status done by the secondary or a tool to do that ?
Yes, sp_BlitzBackups: https://www.brentozar.com/archive/2017/05/announcing-sp_blitzbackups-check-wreck/