
“How many rows exist in a table?”
It seems like such an innocent request. It isn’t too hard to get this information out of SQL Server. But before you open SSMS and whip out a quick query, understand that there are multiple methods to get this information out of SQL Server – and none of them are perfect!
COUNT(*) or COUNT(1)
The seemingly obvious way to get the count of rows from the table is to use the COUNT function. There are two common ways to do this – COUNT(*) and COUNT(1). Let’s look at COUNT(*) first.
|
1 2 |
SELECT COUNT(*) FROM dbo.bigTransactionHistory; |
The STATISTICS IO output of this query shows that SQL Server is doing a lot of work! Over 100,000 logical reads, physical reads, and even read-ahead reads need to be done to satisfy this query.
|
1 2 3 4 |
(1 row(s) affected) Table 'bigTransactionHistory'. Scan count 5, logical reads 132534, physical reads 3, read-ahead reads 131834, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. |
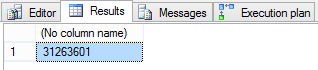
Looking at the execution plan, we can see an Index Scan returning over 31 million rows. This means that SQL Server is reading every row in the index, then aggregating and counting the value – finally ending up with our result set. The cost of this query? 123.910000.

The query results: 31,263,601 rows.
Now, let’s look at the behavior of COUNT(1).
|
1 2 |
SELECT COUNT(1) FROM dbo.bigTransactionHistory; |
We can see from STATISTICS IO that we have a large number of logical reads – over 100,000.
|
1 2 3 4 |
(1 row(s) affected) Table 'bigTransactionHistory'. Scan count 5, logical reads 132531, physical reads 3, read-ahead reads 131849, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. |
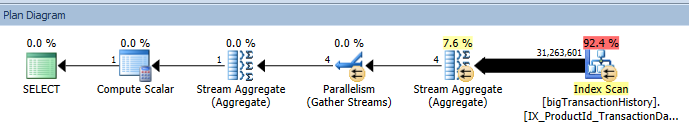
The execution plan again shows an index scan returning over 31 million rows for processing. The query cost is the same, 123.910000.
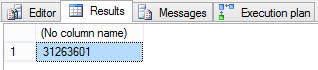
The results here are the same – 31,263,601 rows.
The benefit of using COUNT is that it is an accurate indicator of exactly how many rows exist in the table at the time query processing begins. However, as the table is scanned, locks are being held. This means that other queries that need to access this table have to wait in line. This might be acceptable on an occasional basis, but I frequently see applications issuing these types of queries hundreds or thousands of times per minute.
sys.tables + sys.indexes + sys.partitions
We can join several SQL Server catalog views to count the rows in a table or index, also. sys.tables will return objects that are user-defined tables; sys.indexes returns a row for each index of the table; and sys.partitions returns a row for each partition in the table or index. I am going to query for the table ID, name, and count of rows in all partitions.
|
1 2 3 4 5 6 7 8 9 10 11 |
DECLARE @TableName sysname SET @TableName = 'bigTransactionHistory' SELECT TBL.object_id, TBL.name, SUM(PART.rows) AS rows FROM sys.tables TBL INNER JOIN sys.partitions PART ON TBL.object_id = PART.object_id INNER JOIN sys.indexes IDX ON PART.object_id = IDX.object_id AND PART.index_id = IDX.index_id WHERE TBL.name = @TableName AND IDX.index_id < 2 GROUP BY TBL.object_id, TBL.name; |
The output of STATISTICS IO here shows far fewer reads – 15 logical reads total.
|
1 2 3 4 5 6 7 8 9 |
(1 row(s) affected) Table 'syssingleobjrefs'. Scan count 1, logical reads 2, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. Table 'sysidxstats'. Scan count 2, logical reads 4, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. Table 'sysrowsets'. Scan count 1, logical reads 5, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. Table 'sysschobjs'. Scan count 1, logical reads 4, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. |
The execution plan is more complex, but much less work – the query cost here is 0.0341384.

The results of the query are also the same – 31,263,301.
![]()
The benefits of using this method are that the query is much more efficient, and it doesn’t lock the table you need the count of rows for.
However, you need to be cautious when counting the rows on a table that is frequently inserted into or deleted from. The TechNet documentation for sys.partitions.rows says it indicates the “approximate number of rows for this partition”. How approximate? That information isn’t documented. Understand, though, that if you use this method, you potentially sacrifice up-to-the-moment accuracy for performance.
sys.dm_db_partition_stats
A third option is to use the dynamic management view sys.dm_db_partition_stats. This returns one row per partition for an index.
|
1 2 3 4 5 6 7 8 |
DECLARE @TableName sysname SET @TableName = 'bigTransactionHistory' SELECT OBJECT_NAME(object_id), SUM(row_count) AS rows FROM sys.dm_db_partition_stats WHERE object_id = OBJECT_ID(@TableName) AND index_id < 2 GROUP BY OBJECT_NAME(object_id); |
The STATISTICS IO output of this query is even lower – this time, only two logical reads are performed.
|
1 2 3 |
(1 row(s) affected) Table 'sysidxstats'. Scan count 1, logical reads 2, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. |
The execution plan is less complex than our second example involving the three system views. This query also has a lower cost – 0.0146517.

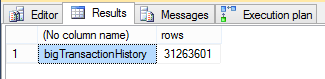
The query results are the same as the previous examples – 31,263,301 rows.
Using this DMV has the same benefits as the system views – fewer logical reads and no locking of the target table. The query is also simpler to write, involving only one object.
But again, the TechNet documentation for sys.dm_db_partition_stats.row_count says it is “the approximate number of rows in the partition”, and when this information is updated is not documented. Here, you are also potentially sacrificing accuracy for performance.
Time to do some digging
The questions that you need to work with the business to answer are, “How up-to-date must the row count be? What is the business purpose? How often do you insert into or delete from that table, and how often do you count the rows?” If the accuracy of the row count is crucial, work to reduce the amount of updates done to the table. If performance is more important, and the row count could be approximate, use one of the system views.
Wanna learn more tricks for free?
Check out our free T-SQL Level Up online class – we guarantee it’s the best T-SQL training trailer you’ve ever seen:

46 Comments. Leave new
Excellent article on a simple task most of us take for granted, thanks. In my shop though most developers don’t have access to the system views but they still want to get the number of rows. I suggest that they use sp_spaceused because it gets the row count from dm_db_partition_stats and avoids the big costly scans.
Great point, John! Thanks.
Great artificial. Just thought that Id mention that your sql examples have been messed up by xml code formatting.
One last thing. Why is it necessary to perform a sum on row_count? Surely the table will either be on the heap or not, it cant be both can it? I am assuming that you meant to be looking for index_id’s < 2.
DECLARE @TableName sysname
SET @TableName = 'bigTransactionHistory'
SELECT OBJECT_NAME(object_id), SUM(row_count) AS rows
FROM sys.dm_db_partition_stats
WHERE object_id = OBJECT_ID(@TableName)
AND index_id < 2
GROUP BY OBJECT_NAME(object_id);
Ooops! Fixed the code samples – thanks for catching that.
I’m summing the count because if the table is partitioned, you’d receive a row for each partition. This example is designed to get the count of the entire table.
Thanks; I didn’t realize that’s how sys.partitions worked but that makes a lot of sense. Once again thanks for the great article.
DBCC UPDATEUSAGE(0) WITH NO_INFOMSGS
SELECT OBJECT_NAME(id), rows FROM sysindexes WHERE indid < 2
This used to work on sql2000 too.
It works in all versions of SQL Server, but even Microsoft says not to run it frequently – it can take a long time on large tables.
Nice!! Quick question… How do I incorporate the where clause to use it with the sys views? The COUNT clauses I have seen usually include joins and where statements but I’m not sure how to fit it in this approach.
Which of the above queries are you referring to?
Why is sys.indexes needed in this?
DECLARE @TableName sysname
SET @TableName = ‘bigTransactionHistory’
SELECT TBL.object_id, TBL.name, SUM(PART.rows) AS rows
FROM sys.tables TBL
INNER JOIN sys.partitions PART ON TBL.object_id = PART.object_id
INNER JOIN sys.indexes IDX ON PART.object_id = IDX.object_id
AND PART.index_id = IDX.index_id
WHERE TBL.name = @TableName
AND IDX.index_id < 2
GROUP BY TBL.object_id, TBL.name;
I’m making sure I count the rows in the clustered index.
Whoops! Good to know, now running and try in production…XD…just joking, but it’s an interesting approach I never saw before or applied myself, surely will use it sooner or later.
Hello!
Years ago, I wrote this piece on the alternatives to SELECT COUNT(*) [http://beyondrelational.com/modules/2/blogs/77/posts/11297/measuring-the-number-of-rows-in-a-table-are-there-any-alternatives-to-count.aspx] – I did not tie it up to the execution plans, however.
The execution plan analysis in this article helps understand the impact of each of these options in a much greater detail.
Thank-you for the post!
If you need the row count quite frequently, an indexed view might also offer a way to bring down the query costs of inferring the number of rows, while adding a little extra cost to all data modification operations.
How about sp_Spaceused ‘Tablename’
That’s another valid option, but I don’t see it in the wild as much as the others. As with other options, this may not be 100% accurate either – you may need to run updateusage to get correct numbers – and that can have an adverse effect on large tables.
yes, But are update statistics different than table update usage?
Sushil – yes, updating statistics is different than doing DBCC UDPATEUSAGE.
number of rows limit in sql table???
The number of rows per table is limited by your available storage.
http://sqlperformance.com/2014/10/t-sql-queries/bad-habits-count-the-hard-way – quite similar, isn’t it? 🙂
Calin – yep, not surprising that other bloggers have the same ideas over time. 😀
Jes, as always great article! Just wanted to add a note regarding the use of SYS.DM_DB_PARTITION_STATS. It is only valid for information for the current database context and it cannot be used to reference another database. So if you were say, comparing counts between tables (like in a publisher/subscriber scenario) I don’t believe you could use this DMV…or could you?
How about powershell? in sqlps : using one line as below….
e.g. :
PS SQLSERVER:\SQL\\DEFAULT\Databases\\Tables> dir | select name, rowcount
Thanks!
Is there any possibility to get the row count based on table column values as parameter.
example
SELECT *
FROM bigTransactionHistory
where column1 = ‘ ‘
Joing with your query :
DECLARE @TableName sysname
SET @TableName = ‘bigTransactionHistory’
SELECT TBL.object_id, TBL.name, SUM(PART.rows) AS rows
FROM sys.tables TBL
INNER JOIN sys.partitions PART ON TBL.object_id = PART.object_id
INNER JOIN sys.indexes IDX ON PART.object_id = IDX.object_id
INNER JOIN bigTransactionHistory
AND PART.index_id = IDX.index_id
WHERE TBL.name = @TableName
AND IDX.index_id < 2
GROUP BY TBL.object_id, TBL.name
Hussain – sure, it involves building dynamic SQL as a string, and executing it. For more information about dynamic SQL, check out Erland’s post:
http://www.sommarskog.se/dynamic_sql.html
Is there any way to apply SYS.DM_DB_PARTITION_STATS on a SQLSERVER View. I have to Count Records from a table based on multiple inner joins. I have half a million records and my Count(ID) Query takes 20 seconds.
Xaveed – generally, you don’t want to join to system tables in end user queries. You can end up with serial (as opposed to parallel) queries, and some ugly locking issues.
The query on sys.partitions can be made simpler, so that it only hits 1 table (same as query on sys.dm_db_partition_stats):
SELECT SUM(p.rows) AS rows
FROM sys.partitions p
WHERE p.object_id = OBJECT_ID(‘MyTable’)
AND p.index_id IN (0,1); — heap or clustered index
Apparently sp_spaceused uses sys.dm_db_partition_stats.
sys.partitions is available to public role, whereas sys.dm_db_partition_stats requires VIEW DATABASE STATE permission.
Would be interesting to see a more detailed comparison of the two views.
[…] to add some non-trivial extra load to that process (or the servers doing said processing). So let’s avoid COUNT(*) shall we? Unfortunately, the top Google results don’t readily point to this, but […]
You have used count(*) in both of the queries. One should be count(1)
exec sp_spaceused
Update for Memory_Optimized tables, which have no clustered index, and whose heap index is not tracked in partition_stats:
SELECT top 1 ps.row_count
FROM sys.indexes as i
INNER JOIN
sys.dm_db_partition_stats as ps
ON ps.object_id = i.object_id
and ps.index_id = i.index_id
WHERE i.object_id = OBJECT_ID(‘dbo.[MyTable]’)
ORDER BY
i.[type] — sort by heap/clust idx 1st
, i.is_primary_key desc
, i.is_unique desc
Can you please make some example get the row count based on table column values as parameter with Hussain question???
This will get (non-zero) rows counts for tables that contain a specific column name.
SELECT OBJECT_NAME(a.object_id), SUM(row_count) AS rows
FROM sys.dm_db_partition_stats a
inner join sys.columns b
on a.object_id = b.object_id
where b.name = ’employid’
and a.object_id = b.OBJECT_ID
AND index_id 0
Somehow in my previous reply the full query string got truncated. Here it is (looking for tables with data containing the column EMPLOYID):
SELECT OBJECT_NAME(a.object_id), SUM(row_count) AS rows
FROM sys.dm_db_partition_stats a
inner join sys.columns b
on a.object_id = b.object_id
where b.name = ’employid’
and a.object_id = b.OBJECT_ID
AND index_id 0
Oh boy!!! It looks like the GT and LT symbols drop code. Here’s the code with those symbols replaced by GT and LT. (Sorry for the multiple posts – moderator feel free to delete previous code-defective comments.)
SELECT OBJECT_NAME(a.object_id), SUM(row_count) AS rows
FROM sys.dm_db_partition_stats a
INNER JOIN sys.columns b
ON a.object_id = b.object_id
WHERE b.name = ’employid’
AND a.object_id = b.OBJECT_ID
AND index_id LT 2
GROUP BY OBJECT_NAME(a.object_id)
HAVING SUM(row_count) GT 0
HI, I need a sample for the below requirement. If the count(customerid) >1 means, for 1st row in count, i need to print ‘M’, and for the second record i need to print ‘N’ and so on. Its tought to query and to get logic. Anybody can help in this?
Anu – sure, click Consulting at the top of the screen.
Action type wise count which are Done on 9/19.
I don’t understand the COUNT(1) example. The code shows COUNT(*), and although one of the values is slightly different, there seems to be no explanation of why the cost is the same.
Adrian – SQL Server optimizes away the * and knows you’re just asking for a count of the number of rows.
The count(1) example still has count(*) in the code-block.
Great eye, James! Fixed.
I appreciate the informative article. For those interested in this topic, I suggest exploring this article (https://www.devart.com/dbforge/sql/studio/sql-server-count-function.html), which describes SQL Server COUNT() and effective row counting.