
In theory, you can add indexes online with SQL Server Enterprise Edition.
In theory, with AlwaysOn Availability Groups, you can add and drop indexes on the primary replica whenever you want.
In theory, you can perform read-only queries on the secondaries whenever you want, and nobody gets blocked.
In practice, these things don’t always add up to the same answer.
I’ve got an AlwaysOn Availability Group demo lab with SQL Server 2014 hosting the AdventureWorks2012 database. I’ll start on my secondary server, and I’ll get all of the suffixes from the Person.Person table:
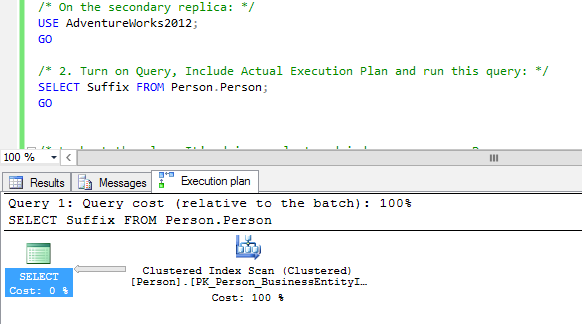
The query results aren’t important – instead, I’m showing the actual execution plan, which is very important. By default, there’s no index on the Suffix field, so I get a clustered index scan.
Say that for some bizarre reason, this is the type of query my end users constantly run, so I decide to switch over to the primary to add an index on Suffix. (As a reminder, you have to add indexes on the primary, not the secondaries.) After adding the index, I run the query again:

Woohoo! We’ve now got an index scan on my new index. (Yeah, it’s not a seek, but this is a crappy query, and a scan is the best I’m going to get.) So far, so good.
But now let’s mix things up a little – let’s run that same query, but start a transaction with it:

Now I have an open transaction, which really shouldn’t mean anything because you can’t do updates on the secondary. However, switch over to the primary, and drop that newly created index. Back over on the secondary, where we’ve got that open transaction, run the exact same query again:

Our transaction has been knocked out and failed. It’s funny to think of a read-only transaction as “failing”, but if you have a stored procedure that starts things off with BEGIN TRAN and then does a lot of reads, thinking it’s going to get a complete point-in-time picture of the data, that’s not going to work.
I know what you’re thinking: “But Brent, I don’t even use snapshot isolation, because I read Kendra’s post about it, and I know we’re not ready to test our app with it yet.” Thing is, SQL Server uses RCSI behind the scenes on all AlwaysOn Availability Group replicas – and it’s lying to you about whether or not the feature is enabled. Here’s the sys.databases view for my secondary replica:

SQL Server claims that for the AdventureWorks2012 database, both snapshot isolation and read committed snapshot are off – but it’s lying to you. Read Books Online about querying the replicas and note:
Read-only workloads use row versioning to remove blocking contention on the secondary databases. All queries that run against the secondary databases are automatically mapped to snapshot isolation transaction level, even when other transaction isolation levels are explicitly set. Also, all locking hints are ignored. This eliminates reader/writer contention.
They’re not kidding – even if I specify dirty reads, I can run into the same problem. Here, I start a transaction, but I’ve asked for the dirtiest, no-lockin-est reads I can get:
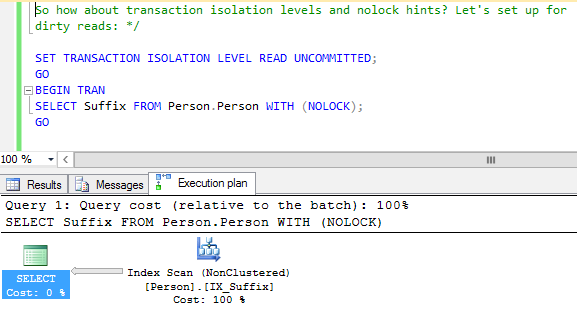
But when I add or drop a related index on the primary, even WITH (NOLOCK) transactions are affected:
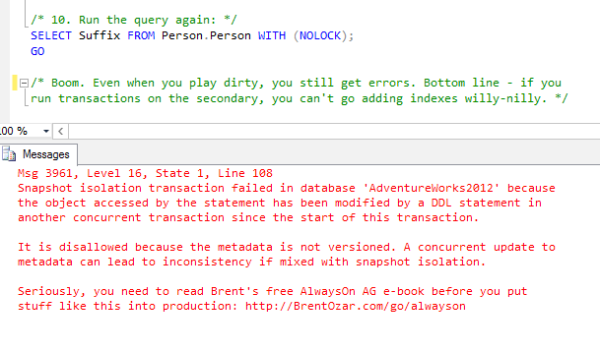
This starts to point to the challenge of running complex reporting jobs off the secondary replicas. SQL Server is constantly changing the data underneath your queries, and most of the time, it cooperates beautifully. However, if you have a long-running stored procedure (like minutes or hours long), and you want a point-in-time picture of the underlying data while you generate reports on the replica, you don’t want to play around with transactions. Instead, a database snapshot might be a better fit.
If you’d like to run these demos on your own lab, download the scripts here.

19 Comments. Leave new
This actually makes me happy for a different reason. Coming into an environment where NOLOCK was declared as standard and required on *everything*, and recently migrating it to AGs, it’s comforting to know that AGs are completely ignoring them the way I thought they were but hadn’t had a chance to prove to myself whether NOLOCK is ignored in a snapshot isolation setting.
That sounds like a scary place to work. =)
Great post – I did the test today in our lab environment as we hit this very issue in production last week whereby an analyst reported this error while running a SELECT statement on an AlwaysOn Secondary.
The table he was selecting from was having an UPDATE STATISTICS run on the Primary but I cannot see any record of Indexes being updated .
Would an UPDATE STATISTICS on an Index or Column that was being referenced from the secondary also cause this error?
Thanks for your help!
Jack – if you’ve got the AlwaysOn environment up and running already, why not run a test to find out? Use the same repro code shown here, but do it with an update statistics instead. It would take less time than writing this comment. 😉
Ha – yes you are correct – of course I thought of this after I wrote it – if there was a recall button I would have pressed it 🙂
So I did the test and was not able to recreate the issue when replacing the DROP INDEX with UPDATE STATS.
Just to be clear Brent, if I run a long query (>10 s) on primary replica and during it’s running I fire up another query on primary replica, will my long query session report RSCI?
Sorry to be lazy but I cannot access my Vmware Lab for now.
SELECT CASE
WHEN transaction_isolation_level = 1
THEN ‘READ UNCOMMITTED’
WHEN transaction_isolation_level = 2
AND is_read_committed_snapshot_on = 1
THEN ‘READ COMMITTED SNAPSHOT’
WHEN transaction_isolation_level = 2
AND is_read_committed_snapshot_on = 0 THEN ‘READ COMMITTED’
WHEN transaction_isolation_level = 3
THEN ‘REPEATABLE READ’
WHEN transaction_isolation_level = 4
THEN ‘SERIALIZABLE’
WHEN transaction_isolation_level = 5
THEN ‘SNAPSHOT’
ELSE NULL
END AS TRANSACTION_ISOLATION_LEVEL
FROM sys.dm_exec_sessions AS s
CROSS JOIN sys.databases AS d
WHERE session_id = @@SPID
AND d.database_id = DB_ID();
Glimo – mine’s powered off too. Since we’re both in the same state, probably easier if you power yours on to answer your question. 😉
hehe, very nice post, nicer answers from Brent and the most amusing sqlserver errormessage I have ever seen 🙂
thank you!
Like!
so a better question what about RO node that is used for reporting? trying to find hidden way that Microsoft shows how indexes are used in this type of AG environment since stats really can’t be updated. Working with vendor on regaining some space on primary RW AG by dumping some indexes but would like to know if used on reporting node
Tim – I’m not sure if you’re asking me a question or just making a comment. If you’re asking a question, can you rephrase it clearly as a question? Thanks!
Hi Brent,
Microsoft documentation and Kendra say it is escalation to Snapshot Isolation, not to RSCI?
Which of the two (RCSI or SI) forces all queries to use the version store, without any changes to the query whatsoever?
RCSI, of course.
Ok, you want to say, first of all, it is escalation to RCSI in the background, plus additional escalation to SI on query level. That makes sense and it is much more understandable if you explain it to readers in this way.
Can you elaborate on what you mean by “additional escalation to SI”?
When we run query on Secondary Replica, Isolation Level is SI not RCSI (e.g. Key Range Lock is possible) – by documentation. What is behind the scene I don’t know because I didn’t find deeper details in Microsoft documentation, but because you wrote “SQL Server uses RCSI behind the scenes” and it is different than documentation, I just guessed that is escalation to RCSI and ” there are additional “escalation” to SI on query level every time when we read data”. I believe you are right, but I am just interested in more details and please explain us how it works behind the scene if you have more information? Thanks.
Let’s step back a little – what’s the problem you’re trying to solve? What are users complaining about that’s leading you to dig into this? I want to make sure we’re both working on something productive.
I am generally interested in more information than Microsoft Documentation offer because we are dealing with big black box, and I have to teach developers in my company what to expect from Secondary Replica when they writing queries – It’s very important is it finally escalation to RCSI or SI.
OK, I think this is pretty far beyond what I can explain quickly in the comments section. You might try posting a question on a forum. Cheers!