
It was a dark and stormy… Oh, wrong story. It was actually a warm, sunny afternoon in Charlotte, NC. I was presenting “Index Methods You’re Not Using” at PASS Summit. In this talk, I discussed how indexed views, filtered indexes, and compressed indexes can improve your query performance by reducing I/O.
From stage right, an intrepid audience member raised his hand and asked, “Can you think of an example of when you would use filtered indexes instead of partitioning?”
This question left me speechless (temporarily).

My first thought was one of requirements and practicality: “What if you have Standard Edition? You can’t use table partitioning, but you could create an indexed view” I said.
The better question would have been, “What are you trying to accomplish?”
On the surface, filtered indexes and partitioning may appear similar: both are designed to hold only portions of a table’s data in separate structures. However, how they go about doing this, the use cases for each, and the requirements for each are very different.
Filtered Indexes
Filtered indexes store only a portion of the data in a table. For example, in an orders table, instead of storing all orders in a nonclustered index on the “quantity” field, we could create a filtered index to only store orders with a quantity greater than or equal to 20, or between 10 and 19. In this case, the only column stored in the index leaf pages is the quantity (and the clustered index key).
Sample of data from the table
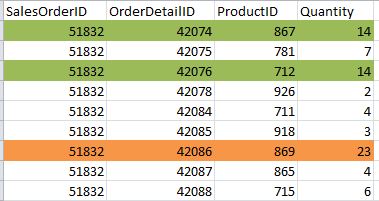
What a nonclustered index on Quantity would store
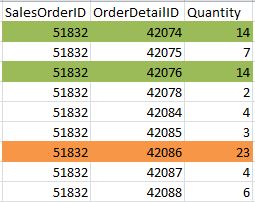
What a nonclustered index on quantity, filtered to include quantity between 10 and 19

Let’s say the data in the underlying table changes – someone wants to increase their order quantity from 750 to 1,250. The row is updated at the data level – the clustered index. At the same time, the nonclustered index must also be updated.
Learn more about filtered indexes by watching The Okapis of SQL Server Indexes, and reading Simple Talk’s Introduction to SQL Server Filtered Indexes.
Table Partitioning
Table partitioning breaks the whole of the data into separate physical structure based on a partitioning key. It’s generally used to improve query performance or make administration of large tables easier. Partitioning is based on a schema and a function. The table contains a partitioning key – the field in the table that contains the value you’ll split your partitions on. Most commonly, this is a date field of one sort or another – tables are partitioned by day, month, or year.
To directly compare this to a filtered index: could you use an order quantity as a partitioning key? Yes, as long as it’s a valid data type. The difference is that the partition is going to store all columns from the table – not just the key. When you insert or update a row, SQL Server would have to look at that value to determine which partition to place it on. It would then perform the update on the appropriate partition.
A table, partitioned on quantity – 1-10, 11-20, 21-30, etc
Partition 1
Partition 2

Partition 3
![]()
Want to know more about partitioning? Start here.
Comparing How They’re Used
When it comes to reading the data, if you have a filtered index for a specific value, and the query optimizer can use that index, you can often reduce I/O by orders of magnitude because you are storing less of the data in the index itself. With partitioning, SQL Server has to determine which partition the data is stored on, then access it. This can be helpful on very, very large tables – but the care and time taken to implement it and the upkeep required mean it must be very carefully considered and maintained.
Which Should I Choose?
There are many features in SQL Server that may appear similar, but once you look at how they work and what they do, they are very different. Database mirroring is not the same as replication. Change Data Capture is not the same as Change Tracking. Filtered indexes and partitioning solve two very different problems. When considering implementing any new feature, stop to ask, “What is the problem I am trying to solve?”

7 Comments. Leave new
Didn’t see it in skimming, sorry if I overlooked it, filtered indexes get their own stats AFAIK. Partitioned tables get the same, upto, 200 steps for the whole table. So filtered indexes can have significant benefits.
Lots of tools, lots of uses. To quote a famous engineer, “The right tool for the night job”. What they don’t tell you is that you still have to know all the tools in your toolbox 🙂
Thanks for the post, so much to learn to get to the level of you guys…
Can we say that as far as it concerns Selects – there is not a big difference (1. choosing the right partition/filtered index, 2. extracting the desired rows),
but when we talk about Update/Insert/Delete – appart of changing the partition/filtered index, in the second option we should also change a huge table?
(The same applies to maintenance plans)
When you insert/update/delete on a table that has a filtered index on it, you’re doing at least two writes – one to the clustered index (or heap, if there isn’t one), and one to the nonclustered (filtered) index. When you insert/update/delete to a table that is partitioned, you’re doing one write – to the clustered index. Any additional nonclustered indexes – in either case – result in another write.
That’s just the same for any nonclustered index though. With a filtered index surely you may or may not write to it depending on whether or not the write affects a record that would show in the index? So if you added filtered indexes to older data, say you were at a company too lazy to archive, but wrote new records into the table then that wouldn’t affect the filtered index.
Although you would have to at least analyse the constraints on the index to know whether or not to write to it. Or am I missing something?
Correct – if the value you are inserting/updating/deleting does not fall within the filtered index value, then that particular nonclustered index is not updated.
Another great article as always. Indexes are always a painful topic.
I am considering partition a Customer’s table with lot of selects, updates and inserts, the table is used all the time for three of them. I am using Sql-Standard 2014. Table is accesed by customer number, it is aprox. 7.000.000 rows, not too big I think. It has already a clustered index by customernumber.
As long as I read this post looks like unless I migrate to Enterprise and use the Partition Wizard this will be a pain and lot of work. Also all the indexes are not well defined according to sp_blitzindex and also simple common sence. But I need a fast and relable solution, may be Table Partition is it.