
We work with SQL Server every day, happily sending and receiving millions of packets of data across the network. Have you stopped to think about what happens when something goes wrong?
The Situation
It’s a regular Tuesday afternoon. Users are happily submitting orders into the shopping cart. After browsing around the website for a while, the users decide that it’s time to buy something. After clicking “Check out now”, the user goes through the check out process, enters their payment information, and then clicks “Buy some stuff!” A few milliseconds later, they get a message that their order was successful and everything is zipping over to their house.
It’s something that we do every day, right? Heck, it’s simple enough that I drew a little diagram:
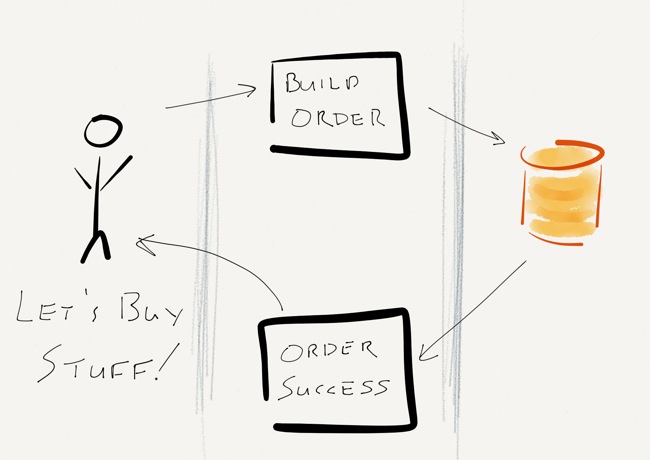
The Problem
What happens when something goes wrong?
There are a lot of places where things could go wrong – a browser bug could prevent form submission, the shopping cart application could go down, the ordering system could be down for maintenance, or SQL Server might even crash (but you’ve configured a solid HA system, so that ain’t gonna happen).
What’s left to fail? The network.
Everything works as it should – the user clicks “Buy some stuff!” and a message is sent to the application servers. The application servers do their magic, approve the credit card, build an order, and save the order in SQL Server. Immediately after SQL Server acknowledges the write and commits the transaction, but before any confirmation is sent to the user, the top of the rack switch power cycles. Randy, the operations intern, accidentally unplugged the power cord before plugging it back in.
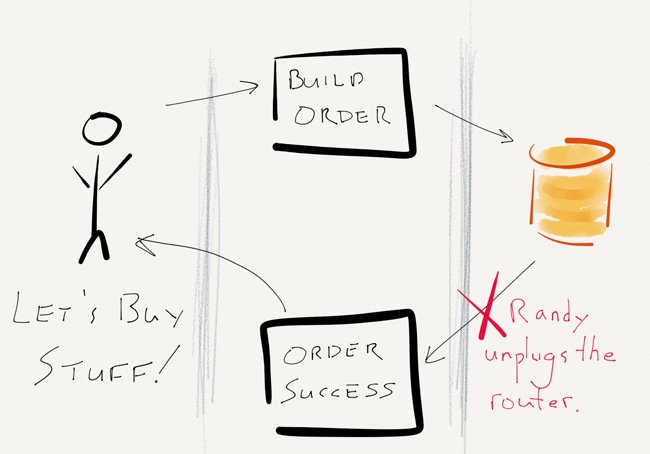
Now What?
This is the part that’s up to you. Sound off in the comments:
- Did the user’s write succeed or fail?
- What does SQL Server think?
- What does the application think?
- Did SQL Server do the right thing?
- What can you do about this sort of thing?
- How can your application handle failures like this?

17 Comments. Leave new
Is this an area where we could use Service Broker? Handle all the user orders with a queue. And send the order confirmation email once the network had been restored.
Well, even in that scenario, what if the write fails after your client has sent the message into Service Broker but before the acknowledgement is sent to the client?
Service Broker can solve sending asynchronous messages and decreasing direct coupling, but that Randy is a tricky janitor and can unplug things at any instant.
Creative use of SB, though. Points to you!
OK, what if we abstract that idea a little higher up the stack? Could we look at MSMQ or BizTalk to orchestrate that?
Let it manage the Order Submission as well as the Conformation Email. Persist the various Queues so that even if the severs were unplugged, they could restart at the proper step.
Well, then you’ve got at least two more problems – MSMQ and thinking that MSMQ was a solution to a problem. And you’re still stuck with the issue of what happens when there’s an unacknowledged write.
Bonus points for being creative, but you’re avoiding the first set of questions – what happens when a successful write response isn’t returned to the client? It doesn’t matter what kind of magic queue you put in place, if a write fails, what do you do?
(Edited this to say “unacknowledged write”, not “uncommitted write”.)
You’re spot on (barring my beliefs about BizTalk and MSMQ’s suitability for anything).
Nothing we can do in SQL Server or ADO.NET will solve this problem – it needs to be abstracted away to a different layer to make sure the application can deal with intermittent network partitions.
In situations like this I beleive a litle more handshaking is in order. The app server should write a record to (or update a column on) the DB once it has sent the order confirmation. Some sort of agent would scour the table at some interval, looking for orders with no confirmation. The folks who have unconfirmed orders should be contacted via e-mail to make sure they wished to proceed (after all, they might have become frustrated and ordered from a competing site).
Should the customer become confused at the lack of communication during the order process, and submitan additional order, this should be accounted for as well. Unconfirmed orders can be compared to other orders submitted before the confirmation was sent and if identical, the customer is contacted again and presented with a set of options, one of which will require doing nothing. (ie if we don’t hear from you within 48 hours, we’ll ship both orders, but we began the shippig process on the first one right away).
I have to agree with Joe on the handshaking. If Randy unplugging the router is something that can happen (and we know that Randy has a bad habit of unplugging the router), then we should design the system such that impact of such a thing is mitigated.
I briefly worked as a 911 operator. When the emergency line rang, we had a very specific protocol to follow, which included the following questions in the following order:
* What is the location of your emergency?
* What number are you calling me from?
* What is happening there?
* Are you safe?
* Is anyone hurt?
This information was extracted in this order in case we lost the connection partway through. If I didn’t know how to call the person back, I could at least start something, anything heading that way. If I didn’t know what was going on, I could try calling them back. If I didn’t know if they were safe, I would at least have an idea of what was going on. And if I didn’t know if anyone was hurt, I would at least know the caller was or wasn’t safe.
A similar situation exists here – a failure at any point should be handled as well as possible. If the user can’t build the order, we’re done here. If the order doesn’t go into the database, tough luck but maybe we can recover with application caching or something, but we don’t charge Jorge’s corporate AmEx if we can’t write to the database. The step between writing to the DB and notifying the user we successfully placed the order is really the weak link, so we’d prefer not to charge Jorge’s corporate AmEx if we didn’t tell Jorge we’re charging it.
I think I might set the application to fire off an alert to a monitoring application if it doesn’t receive an ack from the DB, and then having the monitoring app check if it can connect to the DB and page someone if it can’t (not Randy though, he’d be startled and knock over a rack of equipment.) That would be in addition to requiring the DB to wait on confirmation of confirmation.
Good question!
I think Steve is right, but to expand on this a little, we manage the user experience. Do we think our CC is charged at the moment we click submit on Amazon? We assume it was, but the expectation isn’t as such as we know there can be a delay in that process. This is an a typical problem in distributed systems and the 10 fallacies of networking (I think Udi Dahan’s list is up to 13) need to be mitigated.
Messaging allows us to persist user intent in the event of such failures.
Why is it required that the process be synchronous?
Did the user’s write succeed or fail?
We shouldn’t hold the users experience accountable for network up time, therefore, no need to wait as a user to get “real time” confirmation that the data wrote to the database.
What does SQL Server think?
I am not sure the SQL Server cares. It did what it was asked, persisted the data, and responded. If no one heard the success… If a tree falls in the woods.
What does the application think?
The application technically (IMO) shouldn’t care, it should just know that it passed the users intent back to the powers that be which handle that type of data (the order) and understand we will eventually have consistency. In an Amazon environment the user is never waiting for data to be written to the backing store, this provides for a poor user experiences, blocking the user from continuing about their business. To provide for a better user experience these types of tasks are better handled in an asynch manner and MSQM, or the like, is a fantastic mechanism to allow to mitigate these types of “Randy’s”.
Did SQL Server do the right thing?
IMO, yes, persisted data onto the IO.
There are several steps in the work flow listed, all of which have direct dependencies on other system, or third parties (i.e. payment provider integration). These should not block the User from doing there thing.
In a nutshell, (IMO) these types of processes should not be synchronous.
As developers/ designers/ DBAs, we dictate and control the users experience in the systems we build.
The concept of eventual consistency is perfectly acceptable to users because we dictate what “real time” is via the UI.
“You order is being processed, you should receive an email shortly with your order summary.”
United takes up to 24 hours to deliver my order summary. They’re probably taking into account the time to encode it and feed it into the punchcards.
One more thing, the concept of idempoteny is critical. A command should be able to be run over and over without effecting the underlying data in a negative way (dupes). If the sql server persisted the data and dropped, the service writing that data will actually error.
Basically, if OrderId does not exist, INSERT.
In a Messaging paradigm that message would in effect push to the error queue and retry to process the command again until it gives up and pushes into a special error queue, or is successful.
Great point about idempotency – in these scenarios it’s important that actions can be duplicated.
What follows is a complete guess based on a shaky understanding of this topic. I’d like to hear what you think and whether you think I got anything wrong.
I would imagine SQL Server has successfully committed the transaction.
The success message is not received by the client and if the application is using ADO.net, the application will timeout and attempt to send an alert to the server.
Something similar to the sequence diagrams at:
http://michaeljswart.com/2011/11/insights-into-timeout-expired/
I think that’s what should happen. I’ve never given much thought about how the application should be coded to deal with this. Because I’ve never actually come across this as a problem to be solved. And that’s probably because if network issues are tiny and intermittent, then they’re tolerated by TCP and if the network issues are large and sustained, then that causes much bigger headaches to deal with.
Have you ever come across this as a problem someone’s encountered in real life? Or is this just a problem to be avoided?
You nailed it – SQL Server will correctly commit the transaction and then send the acknowledgement back out to the client. ADO.NET (or any well behaved client) will eventually timeout.
This is more common than you’d think in practice, even if it sounds rare. Steven, Joe, and Ryan hit on some great points of how you can alleviate this by layering with different pieces of software, but this problem can still arise if you aren’t careful.
Very nice post. I’d let the application check that the write was successful in case that the commit-request did not receive a reply. You’d need to make sure that it is reliably possible to check whether the transaction committed or failed, which is always possible. Then retry.
The problem can never be 100% solved. It is the two-generals problem.
The same goes for DTC transactions. They can indeed commit and rollback asynchronously.
I’ll admit I have a little bit different perspective on this as I came into the DBA role from an infrastructure background. You can tell me if I am off topic with this below. I think the application and SQL server questions have been addressed by the above posts, however, there is one perspective I haven’t seen on this is you have to adress the lower level meaning physical concerns first. If you continue to let Randy into the server room who’s to say he doesn’t unplug the SAN or appliation server or SQL server next time he is in there. This is actually a problem that should be addressed by the entire ICT team and not just the DBA or developer. They can do things to adjust for the one possiblity and possibly bullet proof that process, but if Randy is still running around randomly unplugging things you are still going to be dealing with chaos. Who’s to say it’s not Randy but your ISP that is unreliable is a backup/failover connection in order, there are all sorts of issues an incident like this can bring to light and if you don’t address all of them you are inviting a different disaster to happen again.
Hi, Kent. After reading this a couple of times, I’m still not sure – did you have a question in here?
No it was more of a comment about the problem Jeremiah provided and that the if you adjust or account for this incident just at the application or database layer you may be leaving yourself open to further problems. Often with IT we tend to think of solving problems from our perspective, but sometimes with a team based approach we can come up with a better/simpler answer. Maybe it is just as simple as not letting Randy in the server room, or you could spend hours coding around it and ensuring your transactions are bullet proof. What was the real cost to the business of the incident and what is it worth to ensure it doesn’t happen again? You could build an entirely new server room with backup generators, redundant ISP connections coming in through multiple entry points, globally diverse clusters, but does it make sense?
I was also trying to make the point, You can make your transactions bullet-proof, but if it is all still running through a single application server Randy can strike again causing you a costly outage. If you don’t take the time to involve others in your analysis and responce to major incidents for your business you can spend a lot of time solving only part of the problem and not giving a “real” solution.
Hopefully that makes sense…